In the past a few days, I’ve been experimenting with Bazel as a library distribution mechanism for ccv.
I am pretty familiar with hermetic build systems at this point. My main knowledge comes from Buck dating 8 years back. At that time, it never occurred to me such a build system could eventually be a library distribution mechanism. During the same 8 years, NPM has taken over the world. New language-dependent package managers such as Go module, Cargo and Swift Package Manager popularized the concept of using the public repositories (GitHub) as the dependency references. Languages prior to this period, mainly C / C++ are moving to this direction, slowly.
ccv has a simple autoconf based feature detection / configuration system. You would expect the package to work when ./configure && make. However, it never made any serious attempt to be too smart. My initial experience with monorepos at companies strongly influenced the decision to have a simple build system. I fully expect that serious consumers will vendor the library into their monorepo using their own build systems.
This has been true for the past a few years. But as I am finishing up nnc and increasingly using that for other closed-source personal projects, maintaining a closed-source monorepo setup for my personal projects while upstreaming fixes is quite an unpleasant experience. On the other hand, nnc from the beginning meant to be a low-level implementation. I am expected to have high-level language bindings at some point. Given that I am doing more application-related development with nnc in closed-source format now, it feels like the right time.
Although there is no one-true library distribution mechanism for C / C++, there are contenders. From the good-old apt / rpm, to Conan, which has gained some mind-share in the open-source world in recent years.
The choice of Bazel is not accidental. I’ve been doing some Swift development with Bazel and the experience has been positive. Moreover, the choice of high-level binding language for nnc, I figured, would be Swift.
Configure
ccv’s build process, as much as I would rather not, is host-dependent. I use autoconf to detect system-wide libraries such as libjpeg and libpng, to configure proper compiler options. Although ccv can be used with zero dependency, in that configuration, it can sometimes be slow.
Coming from the monorepo background, Bazel doesn’t have many utilities that are as readily available as in autoconf. You can write automatic configurations in Starlark as repository rules, but there is no good documentation on how to write robust ones.
I ended up letting whoever use ccv to decide how they are going to enable certain features. For things like CUDA, such configuration is not tenable. I ended up copying over TensorFlow’s CUDA rules.
Dependencies
Good old C / C++ libraries are notoriously indifferent to libraries dependencies v.s. toolchains. Autoconf detects both toolchain configurations as well as available libraries. These types of host dependencies make cross-compilation a skill in itself.
Bazel is excellent for in-tree dependencies. For out-tree dependencies however, there is no established mechanism. The popular way is to write a repository rules to load relevant dependencies.
This actually works well for me. It is versatile enough to handle cases that have Bazel integrations and have no Bazel integrations.
Consume Bazel Dependencies
Consumption of the packaged Bazel dependencies then becomes as simple as adding git_repository to the WORKSPACE and call proper <your_library_name>_deps() repository rule.
After packaging ccv with Bazel, now Swift for nnc can consume the packaged dependency.
Semantic Versioning Challenges
While the Bazel-provided library distribution mechanism works well for my case, it is simplistic. For one, there is really no good way to do semantic versioning. It is understandable. Coming from a monorepo culture, it is challenging for anyone to dive into dependency hells of library versioning. A slightly different story happened to Go a while back as well.
It is messy if you want to pin a specific version of the library while your dependencies are not agreeing with you. This is going to be messy regardless in C / C++ world, unless you prelink these extremely carefully. Bazel’s philosophy from what I can see, seems largely on keeping the trunk working side. It is working so far, but one has to wonder whether this can scale if more libraries adopted Bazel as the distribution mechanism.
Closing Words
The past a few months experience with Bazel has been delightful. While I would continue to use language specific tools (pip, Go modules, Cargo, NPM) when doing development in that particular language, Bazel is a capable choice for me when doing cross-language development. Concepts such as workspace, git_repository, http_archive fit well within the larger open-source ecosystem. And most surprisingly, it works for many-repo setup if you ever need to.
During the past few years, I’ve been involved in migrations from Xcode workspace based build system to Buck twice (Facebook and Snapchat). Both of these experiences took talented engineers multi-months work with many fixes upstreamed to get it work. Recently, I’ve been helping another company to migrate their iOS project from Xcode workspace based build system to Bazel. This experience may be relevant to other people, considering the Bazel guide is quite light on details.
Why
Why in these companies, people choose to use alternative build tools such as Buck or Bazel but not Xcode? There are a few reasons:
Better Code Review and Dependency Management
Xcode stores its build configurations in both xcscheme files and pbxproj files. None of them are text-editor friendly and heavily rely on Xcode GUI for its configurations. There are ways to only use xcconfig, a text-based configuration file for pbxproj. But for many real-world projects, that is just the third place for build configurations rather than the only source of truth. As a result, configuration changes are impossible to review effectively in any popular web tools (GitHub / Gitlab / Gerrit).
Xcode does dependency management in implicit ways. Thus, you have to create xcworkspace to include all dependent sub-projects for build. This is problematic if you want to split your projects and tests into smaller manageable units. That often ends up with many xcworkspace projects and each need to have manual dependency management and being included in CI tool.
Better Caching and Faster Build Speed
Xcode’s build cache management is quite incompetent. A change in the scheme can result in rebuilding from scratch. Switching between branches can often result in full rebuilding as well.
Bazel is a hermetic build system. If a file or its dependency doesn’t change, a rebuild won’t be triggered. Switching between branches won’t slow down the build because artifacts are cached by its content.
Bazel provided an upgrade path from its primitive disk-based cache system to a distributed remote cache. You can make a switch when the codebase grows or the team grows.
Better Modularization
Swift likes to have smaller modules. Having each module as its own project poses challenges in code review and dependency management. There are alternative solutions such as Swift Package Manager or CocoaPods. Both of them have their unique set of problems (SPM is often too opinionated, while CocoaPods is slow and invasive).
When
Engineering teams often have competing priorities. For many teams, it is unlikely that their starting point will be a Bazel-based project (hopefully this will change in the future). When to prioritize the migration to Bazel? I’ve read it somewhere a good summary on this, and will just put it here: a good time to migrate to Bazel is when you about to need it. If the team starts to feel the pain of Xcode-based build system (multi-minute build time, a ball of mud mono-project, or many small projects but with CI brokages many times every week), it can often take months to do the migration. On the other hand, when you have only 2 people developing an app, it is simply hard to judge the value proposition.
A semi mono-project, with 3 to 4 developers, and some external dependencies (~10 CocoaPods libraries) would be a good place to allocate 1 engineer-week to do the transition. That’s what I did here.
Setup Tooling
The first step of the migration is to set up the tools. We will use Bazelisk to manage Bazel versions, and will symlink Bazelisk to /usr/local/bin/bazel for ease of access. For Xcode integration, we will use Tulsi. It will be installed from source. Both tools are checked out under: $HOME/${Company_Name}/devtools directory. The installation is automated through scripts inside the repository.
Setup Repository Directory Structure
While it is possible to manage external dependencies through WORKSPACE, Bazel loves monorepo. Thus, we are going to vendoring almost all our dependencies into our repository. The repository will be reorganized from a one-project centric layout to a monorepo layout.
1
2
3
4
5
6
7
8
9
10
11
$HOME/${Company_Name}/${Repository}/
- common
- common/bazel_tools
- common/scripts
- common/vendors
- ios/bazel_tools
- ios/Apps
- ios/Features
- ios/Libraries
- ios/Scripts
- ios/Vendors
The Migration
Bazel Basics
If you haven’t, now is a good time to read the Bazel guide for iOS. We first setup an ordinary WORKSPACE file that has rules_apple, rules_swift and xctestrunner imported.
This will allow us to start to use swift_library, swift_binary and ios_application to quickly build iOS app using Bazel.
For Xcode integration, we use the generate_xcodeproj.sh script to create Xcode project with Tulsi. The tulsiproj however, was never checked into our repository. This keeps our Bazel BUILD file the only source of truth for our build configurations.
At this step, we exhausted what we learned from the Bazel guide for iOS and need to face some real-world challenges.
CocoaPods Dependencies
It is hard to avoid CocoaPods if you do any kind of iOS development. It is certainly not the best, but it has accumulated enough popularity that everyone has a .podspec file somewhere in their open-source repository. Luckily, there is the PodToBUILD project from Pinterest to help alleviate the pain of manually converting a few CocoaPods dependencies to Bazel.
First, I use pod install --verbose to collect some information about the existing project’s CocoaPods dependency. This script is used to parse the output and generate Pods.WORKSPACE file that PodToBUILD want to use. We use the bazel run @rules_pods//:update_pods to vendoring CocoaPods dependencies into the repository.
Some dependencies such as Google’s Protobuf already have Bazel support. After vendoring, we can switch from PodToBUILD generated one to the official one. Some of the dependencies are just static / dynamic binary frameworks. We can just use apple_dynamic_framework_import / apple_static_framework_import. Pure Swift projects support in PodToBUILD is something to be desired. But luckily, we can simply use swift_library for these dependencies. They usually don’t have complicated setup.
Some do. Realm is a mix of C++17, static libraries (librealm.a) and Swift / Objective-C sources. We can still use PodToBUILD utilities to help, and it is a good time to introduce swift_c_module that can use modulemap file to create proper Swift imports.
The C++17 portion is interesting because until this point, we used Bazel automatically created toolchains. This toolchain, unfortunately, forced C++11 (at least for Bazel 3.4.1 on macOS 10.15). The solution is simple. You need to copy bazel-$(YourProject)/external/local_config_cc out into your own common/bazel_tools directory. Thus, we will no longer use the automatically generated toolchains configuration. You can modify C++11 to C++17 in the forked local_config_cc toolchain.
Here is what my .bazelrc looks like after CocoaPods dependencies migration:
1
2
3
4
5
6
7
8
9
10
build --apple_crosstool_top=//common/bazel_tools/local_config_cc:toolchain
build --strategy=ObjcLink=standalone
build --symlink_prefix=/
build --features=debug_prefix_map_pwd_is_dot
build --experimental_strict_action_env=true
build --ios_minimum_os=11.0
build --macos_minimum_os=10.14
build --disk_cache=~/${Company_Name}/devtools/.cache
try-import .bazelrc.variant
try-import .bazelrc.local
The Application
If everything goes well, depending on how many CocoaPods dependencies you have, you may end up on day 3 or day 5 now. At this point, you can build each of your CocoaPods dependencies individually. It is time to build the iOS app with Bazel.
There actually aren’t many gotchas for building in the simulator. Following the Bazel guide for iOS and set up your dependencies properly, you should be able to run the app inside the simulator.
If you have any bridging header (which you should avoid as much as possible!), you can add ["-import-objc-header". "$(location YourBridgingHeader.h)"] to your swift_library’s copts.
To run the app from the device, it may need some extra work. First, Bazel needs you to tell it the exact location of provisioning files. I elected to store development provisioning files directly in ios/ProvisioningFiles directory. With more people, this may be problematic to update, since each addition of device or developer certificate requires a regeneration of provisioning files. Alternatively, you can manage them through Fastlane tools.
iOS devices are often picky about the entitlements. Make sure you have the proper application-identifier key-value pair in your entitlements file.
If you use Xcode, now is a good time to introduce the focus.py script. This script will take a Bazel target, and generate / open the Xcode project for you. It is a good idea to have such a script to wrap around generate_xcodeproj.sh. You will inevitably need some light modifications around the generated Xcode project or scheme files beyond what Tulsi is capable of. Here is mine.
You can use such script like this:
1
./focus.py ios/Apps/Project:Project
Dynamic Frameworks
rules_apple in 04/2020 introduced a bug that won’t codesign dynamic frameworks properly. It is not a big deal for people that have no dynamic framework dependency (you should strive to be that person!). For many mortals, this is problematic. Simply switching to rules_apple prior to that commit will fix the issue.
Tests
Bazel, as it turns out, has fantastic support for simulator-based tests. I still remember the days to debug Buck issues around hosted unit tests and alike.
Many projects may start with something called Hosted Tests in the Xcode world. It is quick and dirty. With Hosted Tests, you have full access to UIKit, you can even write fancy SnapshotTesting. However, now is a good time for you to separate your tests out into two camps: a library test and a hosted test.
A library test in Bazel is a ios_unit_test without test_host assigned. It can run without the simulator, and often faster. It is restrictive too. Your normal way of accessing UIImage from the application bundle won’t work. Some UIKit components will not initialize properly without an UIApplicationDelegate. These are not bad! It is great to isolate your test to what you really care about: your own component!
You should move most of your existing tests to library tests.
SnapshotTesting has to be a hosted test. There are also implicit assumptions within that library about where to look for snapshot images. Luckily, we can pass --test_env from Bazel to our test runner and write a wrapper around assertSnapshot method.
The ios_ui_test will just work for your UI tests. The only bug we encountered is about bundle_name. Just don’t modify bundle_name in your ios_application. The ios_ui_test is not happy to run a bundle that is not named after the Bazel target name.
Code Coverage
Bazel in theory have good support for code coverage. You should be able to simply bazel test --collect_code_coverage and it is done. However, at least for the particular rules_apple and 3.4.1 Bazel, I have trouble doing that.
The code coverage is not hard though. Under the hood, Xcode simply uses source based code coverage available from Clang / Swift. We can pass the right compilation parameters through Bazel and it will happily build tests with coverage instrumentation.
1
2
3
4
5
6
7
8
build --copt="-fprofile-instr-generate"
build --cxxopt="-fprofile-instr-generate"
build --linkopt="-fprofile-instr-generate"
build --swiftcopt="-profile-generate"
build --copt="-fcoverage-mapping"
build --cxxopt="-fcoverage-mapping"
build --linkopt="-fcoverage-mapping"
build --swiftcopt="-profile-coverage-mapping"
To run tests with the coverage report, we need to turn off Bazel sandbox to disable Bazel’s tendency of deleting files generated from test runs. LLVM_PROFILE_FILE environment variable needs to be passed through --test_env as well. Here are four lines how I generated coverage report that Codecov.io will be happy to process:
1
2
3
4
bazel test --test_env="LLVM_PROFILE_FILE=\"$GIT_ROOT/ProjectTests.profraw\"" --spawn_strategy=standalone --cache_test_results=no ios/Apps/Project:ProjectTests
xcrun llvm-profdata merge -sparse ProjectTests.profraw -o ProjectTests.profdata
BAZEL_BIN=$(bazel info bazel-bin)
xcrun llvm-cov show $BAZEL_BIN/ios/Apps/Project/ProjectTests.__internal__.__test_bundle_archive-root/ProjectTests.xctest/ProjectTests --instr-profile=ProjectTests.profdata > Project.xctest.coverage.txt 2>/dev/null
CI Integration
It is surprisingly simple to integrate Bazel with CI tools we use. For the context, we use Bitrise for unit tests and ipa package submission / deployment. Since we scripted our Bazel installation, for unit tests, it is as simple as running bazel test from the CI. Both hosted tests and UI tests worked uniformly that way.
There are some assumptions from Bitrise about how provisioning files are retrieved. If you use Fastlane tools throughout, you may not have the same problem.
We end up forked its Auto Provision step to make everything they retrieved from Xcode project the pass-in parameters. At later stage, we simply copied out the provisioning file to replace the development provisioning file from the repo.
Benefits after the Bazel Migration
Apollo GraphQL Integration
Prior to Bazel migration, Apollo GraphQL integration relies on Xcode build steps to generate the source. That means we have tens of thousands lines of code need to be recompiled every time when we build. People also need to install apollo toolchain separately on their system, with node.js and npm dependencies.
We were able to integrate the packaged apollo cli further into Bazel.
1
2
3
4
5
6
7
http_archive(
name = "apollo_cli",
sha256 = "c2b1215eb8e82ec9d777f4b1590ed0f60960a23badadd889e4d129eb08866f14",
urls = ["https://install.apollographql.com/legacy-cli/darwin/2.30.1"],
type = "tar.gz",
build_file = "apollo_cli.BUILD"
)
The toolchain itself will be managed as a sh_binary from Bazel perspective.
1
2
3
4
5
6
sh_binary(
name = "cli",
srcs = ["run.sh"],
data = ["@apollo_cli//:srcs"],
visibility = ["//visibility:public"]
)
1
2
3
#!/usr/bin/env bash
RUNFILES=${BASH_SOURCE[0]}.runfiles
"$RUNFILES/__main__/external/apollo_cli/apollo/bin/node" "$RUNFILES/__main__/external/apollo_cli/apollo/bin/run" "$@"
With genrule and apollo cli, we were able to generate the source code from Bazel as a separate module. In this way, unless the query changed or schema changed, we don’t need to recompile the GraphQL module any more.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
filegroup(
name = "GraphQL_Files",
srcs = glob(["*.graphql"])
)
filegroup(
name = "GraphQL_Schema",
srcs = ["schema.json"]
)
genrule(
name = "GraphQLAPI_Sources",
srcs = [":GraphQL_Files", ":GraphQL_Schema"],
outs = ["GraphQLAPI.swift"],
# Apollo CLI is not happy to see bunch of symlinked files. So we copied the GraphQL files out
# such that we can use --includes properly.
cmd = """
mkdir -p $$(dirname $(location GraphQLAPI.swift))/SearchPaths && \
cp $(locations :GraphQL_Files) $$(dirname $(location GraphQLAPI.swift))/SearchPaths && \
$(location //common/vendors/apollo:cli) codegen:generate --target=swift --includes=$$(dirname $(location GraphQLAPI.swift))/SearchPaths/*.graphql --localSchemaFile=$(location :GraphQL_Schema) $(location GraphQLAPI.swift)
""",
tools = ["//common/vendors/apollo:cli"]
)
CI Build Time
Even Bazel’s disk cache is primitive, we were able to reap the benefit from our CI side. Bitrise CI allows you to push and pull build artifacts. We were able to leverage that to cut our build time by half from Bitrise.
Build for Different Flavors
A select_a_variant Bazel function is introduced. Under the hood, it is based on select and config_setting primitives from Bazel. A simple variant.py script can be added to switch between different flavors.
For different flavors, a different set of Swift macros will be passed in (we wrapped swift_library with a new Bazel macro). Different sets of dependencies can be selected as well. These build options, particularly for dependencies, are difficult to manage with the old Xcode build system.
Code Generation and More Code Generations
We’ve changed the app runtime static configurations from reading a bundled-JSON file at startup to generating Swift code from the same JSON file. I am looking forward to having more code generations and even try a bit of Sourcery now after the Bazel migration. The vanilla genrule is versatile enough and supports multiple outputs (comparing to Buck). Once figured out that swift_binary should belong to the tools parameter of genrule, it is a breeze to write code generation tools in Swift.
Conclusion
Even though there are still some workarounds needed for Bazel. It is night and day compared to my experience with Buck a few years ago. It is relatively simple to migrate a somewhat complicated setup in a few days.
Looking forward, I think a few things can be improved.
PodToBUILD was built with Swift. It cannot parse many Ruby syntax, and can cause failures from that. In retrospect, we probably should have such tool to be built with Ruby. At the end of the day, the CocoaPods build syntax is not complicated. Once you run Ruby through that DSL, everything should be neatly laid out.
Although Bazel is language agnostic. I hope that in the future, we can have a Bazel package manager that is as easy to use as CocoaPods. That probably can be the final nag for many people to use Bazel to start new iOS projects. The WORKSPACE alternative with git_repository is not a real solution. For one, it doesn’t traverse dependencies by default. This is for a good reason if you understand the philosophy behind it. But still, it makes Bazel a harder hill to climb.
Let me know if you have more questions.
At times, a year can be a day and a day can be a year. After the past several years since January 2020, it feels far-reaching nowadays to preach how awesome the human world is. But the progress cannot be stalled, the problem cannot solve itself with inaction.
So, good people continue to publish great works. The recent GPT-3 model shows some interesting abstract reasoning capability. While I still have some trouble to grasp how in-context conditioning works with such a big model. It seems interesting enough that a language model, with inputs of words of trillions, can demonstrate some basic arithmetic and logic understanding.
That’s probably because we have too many words, to name things, to show emotions, to communicate abstract concepts, and to describe this beautiful world. That is also why I am sad when people erase meanings from words. And when that happens, a small part of our shared consciousness dies.
When communism becomes simply satanic, who needs to read The Road to Serfdom to understand when central planning from so-called leaders can become the tyranny of dictatorship.
But here we are. Anti-fascism is the foundation of the post-WWII order. From Leningrad to Paris, from Saigon to Washington D.C., on both sides of the Berlin Wall, if there is one thought that connects people together, that is never-again for fascism.
Today, one man tries to erase one word. They chanted: war is peace, freedom is slavery, anti-fascism is fascism.
I am not a native English speaker. Sometimes I have trouble to differentiate between the hundreds of ways to insert please. But I love to learn new words. English is so powerful precisely because we shamelessly borrow words. We say chutzpah to describe how gutsy someone is. We call a person kaizen master to praise the continuous improvement efforts they put in place. The meaning of a word can change, but all these meanings become the historical footnotes. Words establish a common ground for us to start understanding each other.
Maybe there is a future version where we speak a sequence of 128d vectors, arguing between the L1 or L2 distances of these vectors. It could be high-bandwidth. Or there may be a future we learn from videos rather than words (and short videos can certainly be educational: https://youtu.be/sMRRz1J9RkI). But today, a compact word is still our best way to communicate big ideas, to grasp the complex reality that sometimes can be overwhelming.
And that is why the literacy in words, in the past 70 years, is our best defense against colonialism, extremism and fascism.
Use Wikipedia, go read the footnotes, don’t trivialize a word. Our world depends on it.
I had some of the fondest memories for Visual Basic in 1998. In January, I enlisted myself to a project to revive the fun part of programming. There are certain regrets in today’s software engineering culture where we put heavy facades to enforce disciplines. Fun was lost as the result.
With Visual Basic, you can create a GUI and start to hack a program in no time. You write directives and the computer will obey. There are certain weirdnesses in the syntax and some magic in how everything works together. But it worked, you can write and distribute a decent app that works on Windows with it.
When planning my little series the fun part of programming, there is a need to write cross-platform UI outside of Apple’s ecosystem in Swift. I picked Swift because its progressive disclosure nature (it is the same as Python, but there are other reasons why not Python discussed earlier in that post). However, the progressive disclosure ends when you want to do any UI work. If you are in the Apple’s ecosystem, you have to learn that a program starts when you have an AppDelegate, a main Storyboard and a main.swift file. On other platforms, the setup is completely different, even if it exists at all.
That’s why I spent the last two days experimenting whether we can have a consistent and boilerplate-free cross-platform UI in Swift. Ideally, it should:
- Have a consistent way to build GUI app from the Swift source, no matter what platform you are on;
- Progressive disclosure. You can start with very simple app and it will have the GUI show up as expected;
- Retained-mode. So it matches majority of UI paradigms (on Windows, macOS, iOS and Android), easier for someone to progress to real-world programming;
- Can still code up an event loop, which is essential to build games.
After some hacking and experimenting, here is what a functional GUI app that mirrors whatever you type looks like:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
import Gui
let panel = Panel(title: "First Window")
let button = Button(title: "Click me")
let text = Text(text: "Some Text")
panel.add(subview: button)
panel.add(subview: text)
let childText = TextInput(title: "Text")
childText.multiline = true
let childPanel = Panel(title: "Child Panel")
childPanel.add(subview: childText)
panel.add(subview: childPanel)
button.onClick = {
let panel = Panel(title: "Second Window")
let text = Text(text: "Some Text")
panel.add(subview: text)
text.text = childText.text
childText.onTextChange = {
text.text = childText.text
}
}
You can use the provided build.sh to build the above source on either Ubuntu (requires sudo apt install libglfw3-dev and Swift 5.2.1) or macOS (requires Xcode 11):
1
./build.sh main.swift
and you will see this:
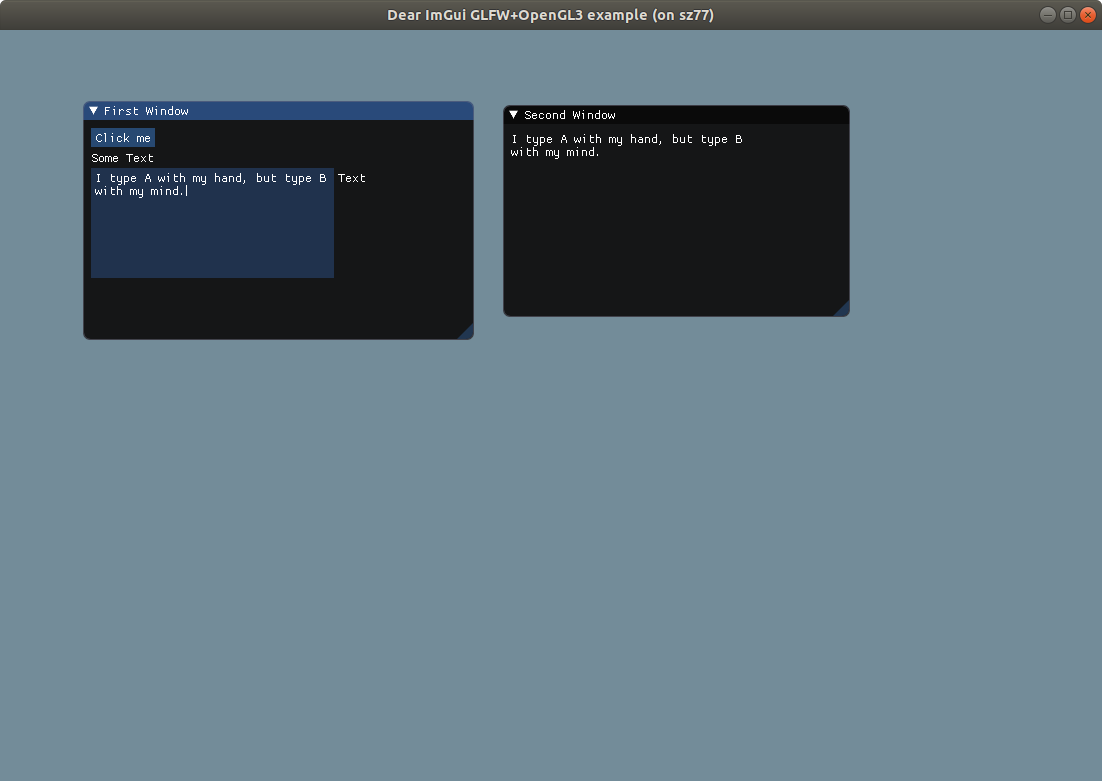
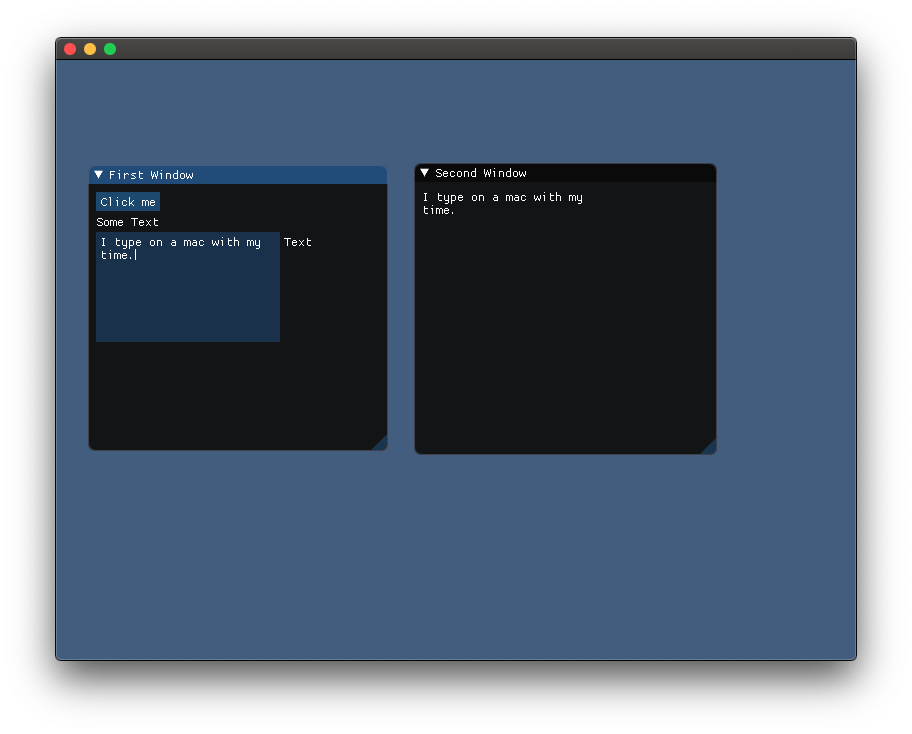
Alternatively, you can build an event loop all by yourself (rather than use callbacks):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
import Gui
let panel = Panel(title: "First Window")
let button = Button(title: "Click me")
let text = Text(text: "Some Text")
panel.add(subview: button)
panel.add(subview: text)
var onSwitch = false
var counter = 0
while true {
if button.didClick {
if !onSwitch {
onSwitch = true
} else {
onSwitch = false
}
}
if onSwitch {
text.text = "You clicked me! \(counter)"
} else {
text.text = "You unclicked me! \(counter)"
}
counter += 1
Gui.Do()
}
In fact, the Gui.Do() method is analogous to DoEvents that yields control back to the GUI subsystem.
The cross-platform bits leveraged the wonderful Dear imgui library. Weirdly, starting with an immediate-mode GUI library makes it easier to implement a retained-mode GUI subsystem that supports custom run loops well.
You can see the proof-of-concept in https://github.com/liuliu/imgui/tree/swift/swift. Enjoy!
There are some articles referring to the past 20 years as the modern Gilded Age. While Gilded Age is an American specific reference, it nevertheless carries a certain western culture mark in the early 20th century. However, the characterization of the Gilded Age, particularly railroads v.s. the internet, would come across to me as lazy. The fanatic obsession with literal bits over atoms comparison can delight certain readers, by and large, it failed to account for the scientific breakthroughs we accomplished in the physical world during the past 30 years. The modern Gilded Age would happily talk about income inequality and wealth gaps between the people and the super rich. While the class-struggle is real, the rather American centric view doesn’t help frame the issues in many other places during the Globalization. The last Gilded Age ended with a Great war. With the rising tide of Nationalism today, the non-cooperation between nations is a greater threat than another war.
The ruthless Globalization in the past century gives us a more interconnected world. This world brings new hopes, poses brand new challenges and unveils new ugliness in ourselves. The obsession with analogies of the old can only blind us with challenges at the hand and impede new progresses we have to make.
The Bits over Atoms Fallacy
The typical Silicon Valley’s talk would often revolve around bits versus atoms. It immediately draws a cheap analogy to railroads’ giants and today’s big tech corps. While the analogy is apparently appealing (railroads to fibers!), the modern days big tech corps don’t build the digital railroads. They assimilate, curate and disseminate information to you and of you. Today, the seemingly boundless “bits” is a result of all powerful service-based industries in the United States. These service-based industries only matter because the ever growing greed for profit margin. Globally, wealth is more diversely distributed than just finance and technology sectors. The list of top 10 richest people in the United Kingdom own very different things compared with their counterparts in the United States.
Technologies continue to shape our lives in important ways. But sweeping all the advances under the rug of digitalization wishfully ignores innovations in new materials, new manufacturing progresses and even the dearest new chip productions. The fallacy of bits over atoms emphasizes the form (bits) over the underlying function enabler (atoms) while the rapid progress of underlying function enablers drives us to new heights. Hopefully, over the next few years, people will rediscover the atoms as the moat for their competition again.
The Income Inequality Fallacy
The wealth gap analysis from Capitalism in the 21st Century was well-known. In the United States, the wealth gap was trivialized as the income inequality. The politicians are either too lazy or too dumb to discuss the the difference between wealth gap and income inequality. While it is true that in Europe, the income inequality was derived from wealth gaps (income generated from wealth far outpaced the income generated from labor). Professional managers are the new class in the United States that drive the income inequality.
The inequality of income as a signature symptom of the Gilded Age draws another analogy to the modern time. The dynamics of wealth destruction and creation in the United States however make it another lazy attempt to paint over another problem. Besides the income generated from wealth inherited through generations, both the career path of a professional manager and the wealth creation through destructive innovations can generate outsized income for people in the game. When means of production were outsourced to other nations, it can only be a limited argument to explain income inequalities.
While the wealth gap in the United States becomes a pure social structure play, the income inequality is a fallacy because it willingly ignores that the trouble is have nots, not haves. What prevents us from lifting the living standard for all as a society? Why haves can deprive resources from have nots? We as a society only recently have left the world of scarcity (with the Green Revolution?), it is doubtful that the artificial scarcity we created through privileges (luxury goods) will be the resources we deprive from have nots. As a society, we ought to have smarter solutions than going straight to the fallacy derived from the old scarcity world.
The more interesting question is about the developing world. If the United States entered the society of abundance, why the rest are not? Does the United States live in abundance because of technology breakthroughs, or on the back of its world dominance? These questions can find their references in historical context, but we need to have a new perspective to lift the living standard for everyone on the planet Earth.
The Great War Fallacy
The Gilded Age ended with WWI, and soon after, the Great Depression and WWII. It is never clear to me why people, especially men, have this enthusiasm with global warfare. Regional conflicts and ongoing tit-for-tat military operations will continue to be what they are. The Great War fallacy is deeply rooted in the belief that military conflicts can be effective means to advance one superpower’s objective against another. With the recent uprising of nationalism and xenophobia, this outdated view finally finds some of its consolation. It is all too familiar to draw an analogy of a new rising world power (Germany) against the old (British). That has been said, the mutual destruction power, the Globalization and the belief of a rule-based system are still very much alive in our modern world. However, the biggest fallacy of the new Great War is that there is nothing to bet on. There is not going to be a world after another Great War. Thus, believing in this fallacy has no relevance to our daily lives.
Although a war is meaningless to speculate on, the non-cooperation between superpowers could deteriorate the progress we have made so far. The soil for xenophobia and nationalism are richer than ever. While the dream of Globalization by elites is very much alive, the answer to why and an appeal to our better nature is desperately needed.
With a world-wide plague, an all-out trade-war, and the great fires from Climate Change, in these trying times, seeking a better tomorrow for our modern world can not be more critical. Analogies with old times are slides for the old man to swipe through on a sunny afternoon; it is an intellectual laziness. We ought to navigate our time more thoughtfully, with a hope and widened eyes. Doomsayers can always be right, but the future belongs to the dreamers.
Yesterday, I was listening to an interview by Oxide Computer people with Jonathan Blow on my way back to San Francisco. There were usual complaints about how today’s programmers buried themselves into the pile of abstractions. As a game programmer Jonathan Blow himself, they also discussed some fond memories about programming basic games in his childhood. All that kept me thinking, how uninteresting today’s programming books are! They start with some grand concepts. Compilers! Deep learning! GPGPU programming! SQL! Databases! Distributed systems! Or with some kind of frameworks. React! iOS! TensorFlow! Elasticsearch! Kubernetes! Is it really that fun to learn some abstractions people put up with? Seriously, what is the fun in that?
Over the years, I learned that there are two kinds of people. The first one loves to create programs that people can use. They take joy from people using the program they create. The magic satisfaction came from observing people using this thing. The second one loves to program. They take joy from solving the interactive puzzle through programming. The fact that the program can do non-obvious tasks by itself is enjoyable, no matter whether these tasks have practical use or not. As for myself, I love to solve puzzles, and understand every last detail about how these puzzles are solved. At the same time, I take pride in people using the software I built.
My earliest memories with programming came from Visual Basic and Delphi. These were RAD tools (Rapid-Application-Development) back in the late 1990s. They were integrated environments to shoot-and-forget when it came to programming. They were not the best to help understand computer architecture ins-and-outs. To some extent, they were not even that good at developing efficient programs. But there are two things they did really well: 1. it was really easy to jump in and write some code to do something; 2. things you made can be shared with others and ran on most Windows computers like the “real” applications would do. At that time, there were a lot of magazines and books that teach you how to make useful things. From a simple chat room, to a remake of the Breakout game, you can type in the code and it would run! Then there were spiritual successors. Flash later evolved into Flex Builder, that meant to use Java-like syntax but preserves the spirit of RAD environment. As of late 2000s, you could build a SWF file and it would run almost everywhere. There were millions of amazing games built with Flash / Flex Builder by amateurs now live in our collective online memory.
Writing the iOS app in the 2010s somewhat gave me similar feelings. But the wheel moved on. Nowadays, we have MVVM / VIPER / RIB patterns. We have one-way data flow and React. We invented concepts to make programming more robust and productive in industrial settings with these abstractions. But the fun part was lost.
That is why this year, I plan to write a series to remind people how fun it is to program. It won’t be a series about frameworks and patterns. We will pick the simplest tool available. We will write code in different languages if that is what’s required. We will maintain states in globals when that makes sense. We will write the simplest code to do fun things. It will work and you can show it to your friends, distribute it as if it was made by professionals.
I would like to cover a broad range of topics, but mostly, just practical things you can build. There certainly will be a lot of games. Some of the arrangements I have in mind, in this particular order:
- A street-fighter like game. Introduce you to game loops, animation playback, keyboard events and coordinate system.
- A remake of Super Mario 1-1 with a level editor. With physics simulation, mouse events and data persistence.
- A chat room with peer-to-peer connection over the internet. Introduce the ideas of in-order message delivery and the need for protocols.
- Remake Super Mario into a multiplayer side-scrolling game like Contra (NES). (this may be too much plumbing, I need to feel about it after the first 3 chapters).
- Chess, and the idea of searching.
- Online Chess with people or more powerful computers.
- Secure communication through RSA and AES.
- Why don’t implement your own secure protocols (show a few hacks and defenses around the protocols above).
- Geometry and explore the 3D of DOOM. Introduce the graphics pipeline. I am not certain whether to introduce GPU or not at this point.
- Face recognition with a home security camera. Introduce convolutional networks and back-propagation. Likely use a simple network trained on CIFAR-10, so everything will be on CPU.
- Convolutional networks and Chess, a simple RL.
There are many more topics I’d like to cover. I would like to cover some aspects of natural language processing through machine translation, either RNN or Transformer models. It is however challenging if I don’t want to introduce GPGPU programming. I also would like to cover parsers, and a little bit of persisted data structures. But there are really no cool applications at the moment with these. Raytracer would be interesting, but it is hard to fit into a schedule other than it looks kind of real? Implementing a virtual machine, likely something that can run NES games would be fun, but that is something I haven’t yet done and don’t know how much plumbing it requires.
All the arrangements will be built with no external dependencies. We are going to build everything from scratch. It should run on most of the platforms with a very simple dependency I built, likely some kind of Canvas / Communication API. This is unfortunate due to several factors: 1. We don’t have a good cross-platform render API except HTML / JavaScript / TypeScript. 2. Most of our devices are now behind NAT and cannot talk to peers through IP addresses. The Canvas API would provide simple controls as well, such as text input boxes and scroll views. That also means the API will be pretty much in retained mode.
For the tool of choice, it has to be a language that professionals use. There are quite a few candidates nowadays. Python, Ruby, Julia, Swift and TypeScript are all reasonable choices. TypeScript has excellent cross-platform capability and I don’t really need to do much for the Canvas API. Python and Ruby all have libraries you can leverage to do both the Canvas API and Communication. However, I want to do a bit more raw numeric programming. For the speed, Python, Ruby and TypeScript are just not that great. Yes, there is numpy / numba, but what is the fun if I start to call numpy, PyTorch and millions of other Python packages do anything and everything for me? For Julia, I simply need to build too much myself to even get started.
There are many downsides with Swift too. For one, I still need to build a ton to support Windows and Linux. The language itself is too complicated especially with weak references and automatic reference count. Luckily, early on, Swift subscribed to the progressive disclosure philosophy. I will try to avoid most of the harder concepts in Swift such as generics, protocols and nullability. Will try to delay the introduction of weak reference as late as possible. Whenever there is a choice between struct and class, I will go with class until there is a compelling reason to introduce struct in some chapters. I also don’t think that I need to introduce threads or GCD. This probably depends on whether I can come up with an intuitive Communication API.
For the platform to run, I will prioritize macOS, Windows 10 and Ubuntu Linux on Jetson Nano. Keyboard and mouse will still be assumed as main input devices. Jetson Nano would be a particularly interesting device because that would be the cheapest to run with some GPGPU programming capability. I am not certain whether I want to introduce that concept. But having that flexibility is great.
Interested?
The past 3 months ought to be the best 3 months for television shows. As a prolific TV viewer, the shows from the past 3 months are all impressive and well-executed. Some of these due to better technologies. Some of these we can probably thank to the investment coming from the streaming war. The pouring of money and talents certainly worked. On top of all these, one of the most interesting turns in the past a few months is the prolific international shows on Netflix. From Better than Us, Kingdom, The Untamed to Ad Vitam, Netflix is uniquely positioned to provide some international flavors to the U.S. viewers.
For All Mankind
The new Apple TV+ show gives a good 90s vibe when we still have The West Wing and Star Trek TNG. The future is hopeful, and the leaders are altruistic. It sets itself apart from the more recent twisted and darker themes from The Walking Dead to Breaking Bad. We had too many of these in this decade.
The Expanse Season 4
I’d be honest that this season is a bit dense and I am still working through it. But hey, it is back! No matter how few space operas we made this decade, or as a genre, it is dead to many. Somehow we made the best space opera yet with The Expanse (or do we?).
The Witcher
This is a surprise to me. Some of Netflix’s recent dump of fantasy / sci-fi genre such as The Umbrella Academy and Lost in Space are not exactly a runaway success. I liked Altered Carbon, but not many people share the same view. But The Witcher has to be one of the best game adaptation Netflix, or anyone had made so far. To someone has no background on the novel or the games, it is easy to consume. The 3 split timelines in the beginning are not that hard to follow and it gets merged relatively quickly. It has the right mix of independent stories and the main storyline. Comparing with other fantasy series such as Game of Thrones, the background is not as grandiose, but comparably interesting. Comparing to similar nordic origin Grimm, the character development is simply miles better.
The Mandalorian
Who says space opera as a genre is dead again? The Mandalorian if keeps its current momentum, would certainly cement a good position for Disney+ in the streaming war. It has some weaker episodes, but the storyline was kept on the right track. The baby yoda is a quick catcher but the Mandalorian himself starts to develop some very interesting background and characters. Besides the story, which always gave me an easy and enjoyable Friday night, the special effect is also superb. It is generally bright (Tatooine does have 2 suns), that contrasts itself from other sci-fi series often in a darker setup (in general, fewer light sources are easier to render) probably thanks to Disney+’s budget. The new movie-like special effect quality is less about awe you, but to keep the storytelling part unimpeded. I believe to many viewers, they don’t really feel the special effect.
To put the cherry on the top, all shows above now supports 4K HDR (with the exception of The Expanse, I think it only does 4K). The TV streaming nowadays is such a great experience if you can afford it and have Gbps internet connection :) Hope you all enjoyed these great TV shows as I do in this holiday season, and keep warm!
Grand Central Dispatch is the de-facto task-based parallelism / scheduling system on macOS / iOS. It has been open-sourced as libdispatch and ported to many platforms including Linux and FreeBSD.
libdispatch has been designed to work closely with the Clang extension: Blocks. Blocks is a simple, yet powerful function closure implementation that can implicitly capture variables to facilitate the design of task-based parallelism systems.
That choice imposed some constraints when designing the QoS classification system for libdispatch. Blocks’ metadata is of the Clang’s internal. It would leave a bad taste if we were required to modify Clang in order to add Blocks based QoS information. It would be interesting to discover how libdispatch engineers overcame these design dilemmas.
There are also some API limitations for the Blocks’ QoS API. We cannot inspect the QoS assignments for a given block. That makes certain wrappers around libdispatch APIs challenging. For example, we cannot simply put a wrapper to account for how many blocks we executed like this:
1
2
3
4
5
6
7
8
static atomic_int executed_count;
void my_dispatch_async(dispatch_queue_t queue, dispatch_block_t block) {
dispatch_async(queue, ^{
++executed_count;
block();
});
}
The above could have unexpected behavior because the new block doesn’t carry over the QoS assignment for the block passed in. For all we know, that block could be wrapped with dispatch_block_create_with_qos_class. Specifically:
1
dispatch_block_t block = dispatch_block_create_with_qos_class(DISPATCH_BLOCK_ENFORCE_QOS_CLASS, QOS_USER_INITIATED, 0, old_block);
If dispatched, would lift the underlying queue’s QoS to QOS_USER_INITIATED. However, with our wrapper my_dispatch_async, the QoS assignment will be stripped.
We would like to have a way at least to copy the QoS assignment over to the new block. This requires to inspect libdispatch internals.
What is a Block?
Blocks is the function closure implementation from Clang that works across Objective-C, C and C++. Under the hood, it is really just a function pointer to a piece of code with some variables from the calling context copied over. Apple conveniently provided a header that specified exactly the layout of the Block metadata in memory:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// ...
struct Block_descriptor_1 {
unsigned long int reserved;
unsigned long int size;
};
// ...
struct Block_layout {
void *isa;
volatile int32_t flags; // contains ref count
int32_t reserved;
void (*invoke)(void *, ...);
struct Block_descriptor_1 *descriptor;
// imported variables
};
// ...
The first two fields just so happen to match the Objective-C object’s memory layout. This will facilitate the requirement for Objective-C compatibility especially with ARC. The whole Block moved to the heap along with the imported variables in one allocation. Thus, if you have the pointer to the block metadata, you can already inspect captured variables if you know the exact order of their capturing.
At runtime, once a block is called, the compiler will restore the captured variables, and then cast and invoke block->invoke as if it is a normal function.
The Additional Block Metadata
As we can see, the Block_layout is relatively tight with no much space for additional block metadata. How libdispatch engineers find the extra space for the QoS information?
The answer lies in another indirection:
https://github.com/apple/swift-corelibs-libdispatch/blob/master/src/block.cpp#L113
1
2
3
4
5
6
7
8
9
10
11
dispatch_block_t
_dispatch_block_create(dispatch_block_flags_t flags, voucher_t voucher,
pthread_priority_t pri, dispatch_block_t block)
{
struct dispatch_block_private_data_s dbpds(flags, voucher, pri, block);
return reinterpret_cast<dispatch_block_t>(_dispatch_Block_copy(^{
// Capture stack object: invokes copy constructor (17094902)
(void)dbpds;
_dispatch_block_invoke_direct(&dbpds);
}));
}
dispatch_block_create or dispatch_block_create_with_qos_class ultimately calls into this _dispatch_block_create private function.
It captures a particular variable dbpds that contains numerous fields onto the block, and then invoke the actual block directly.
As we can see in the previous section, it is relatively easy to inspect the captured variables if you know the actual layout. It just happens we know the layout of struct dispatch_block_private_data_s exactly.
Copying QoS Metadata
Back to the previously mentioned my_dispatch_async implementation. If we want to maintain the QoS metadata, we need to copy it over to the new block. Now we have cleared the skeleton, there are only a few implementation details.
First, we cannot directly inspect the captured variables.
It is straightforward to cast (struct dispatch_block_private_data_s *)((uint8_t *)block + sizeof(Block_layout)), and then check the fields. However, there is no guarantee that a passed-in block is wrapped with dispatch_block_create method always. If a passed-in block happens to contain no captured variables, you may access out-of-bound memory address.
The way libdispatch implemented is to first check the invoke function pointer. If it is wrapped with dispatch_block_create, it will always point to the same function inside the block.cpp implementation. We can find this function pointer at link time like what libdispatch did or we can find it at runtime.
1
2
3
4
5
6
7
8
9
10
typedef void (*dispatch_f)(void*, ...);
dispatch_f dispatch_block_special_invoke()
{
static dispatch_once_t onceToken;
static dispatch_f f;
dispatch_once(&onceToken, ^{
f = (__bridge struct Block_layout *)dispatch_block_create(DISPATCH_BLOCK_INHERIT_QOS_CLASS, ^{})->invoke;
});
return f;
}
Second, we need to deal with runtime changes. We don’t expect libdispatch has dramatic updates to its internals, however, it is better safe than sorry. Luckily, struct dispatch_block_private_data_s has a magic number to compare notes. We can simply check dbpds->dbpd_magic against library updates and corruptions.
Finally, we can assemble our my_dispatch_async method properly.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
static atomic_int executed_count;
void my_dispatch_async(dispatch_queue_t queue, dispatch_block_t block) {
dispatch_block_t wrapped_block = ^{
++executed_count;
block();
};
struct Block_layout *old_block_layout = (__bridge struct Block_layout *)block;
if (old_block_layout->invoke == dispatch_block_special_invoke()) {
wrapped_block = dispatch_block_create(DISPATCH_BLOCK_INHERIT_QOS_CLASS, wrapped_block);
struct Block_layout *wrapped_block_layout = (__bridge struct Block_layout *)wrapped_block;
struct dispatch_block_private_data_s *old_dbpds = (struct dispatch_block_private_data_s *)(old_block_layout + 1);
struct dispatch_block_private_data_s *wrapped_dbpds = (struct dispatch_block_private_data_s *)(wrapped_block_layout + 1);
if (old_dbpds->dbpd_magic == 0xD159B10C) {
wrapped_dbpds->dbpd_flags = old_dbpds->dbpd_flags;
wrapped_dbpds->dbpd_priority = old_dbpds->dbpd_priority;
}
}
dispatch_async(queue, wrapped_block);
}
This new my_dispatch_async wrapper now will respect the block QoS assignments passed in, you can check this by dispatch a block with dispatch_block_create and observe the executed QoS with qos_class_self().
Closing Thoughts
The implementation of QoS in dispatch block is quite indigenous. However, it does present challenges outside of libdispatch scope. This implementation is specialized against dispatch_block_t type of blocks, you cannot simply extend that to other types of blocks. I am particularly not happy that dispatch_block_create is not a generic function such that any given block, parameterized or not can have QoS wrapped and somehow respected (for example, taking its QoS out and assign it to a plain dispatch_block_t when you do dispatch_async dance).
Implementing your own QoS-carrying block this way would be quite painful. Each parameterized block would require a specialized function that carries the QoS information. You probably can do that with C macro hackery, but that would be ugly too quickly. You’d better off to have an object that takes both the block and QoS information plainly, than trying to be clever and embedding the QoS information into the block.
I’ve discussed a stackful coroutine implementation to coordinate CUDA stream last year.
That was an implementation based on swapcontext / makecontext APIs. Increasingly, when I thought about porting nnc over to WASM, it becomes problematic because these APIs are more or less deprecated. Popular libc implementations such as musl don’t have implementation of these methods.
After the article, it became obvious that I cannot swapcontext into the internal CUDA thread (that thread cannot launch any kernels). Thus, the real benefit of such stackful coroutine is really about convenience. Writing a coroutine that way is no different from writing a normal C function.
This is the moment where C++ makes sense. The coroutine proposal in C++20 is a much better suit. The extra bits of compiler support just make it much easier to write.
If we don’t use swapcontext / makecontext, the natural choice is either longjmp / setjmp or good-old Duff’s device. It is a no-brainer to me that I will come back to Duff’s device. It is simple enough and the most platform-agnostic way.
There are many existing stackless coroutines implemented in C. The most interesting one with Duff’s device is Protothreads. To me, the problem with Protothreads is its inability to maintain local variables. Yes, you can allocate additional states by passing in additional parameters. But it can quickly become an exercise and drifting away from a simple stackless coroutine to one with all bells-and-whistles of structs for some parameters and variables. You can declare everything as static. But it is certainly not going to work other than the most trivial examples.
I’ve spent this weekend to sharpen my C-macro skills on how to write the most natural stackless coroutine in C. The implementation preserves local variables. You can declare the parameters and return values almost as natural as you write normal functions.
Here is an example of how you can write a function-like stackless coroutine in C:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
static co_decl_task(ab_t, _coroutine_a, (const int a, const int b), private(
int i;
)) {
printf("param a %d\n", CO_P(a));
printf("param b %d\n", CO_P(b));
CO_V(i) = 2;
printf("%d\n", CO_V(i));
co_yield((ab_t){
.a = CO_V(i)
});
CO_V(i) += 1;
printf("param b %d\n", CO_P(b));
printf("%d\n", CO_V(i));
co_yield((ab_t){
.a = CO_V(i)
});
co_return((ab_t){
.a = 10
});
} co_end()
static co_decl_task(int, _coroutine_b, (), private(
co_routine_t* task_a;
ab_t a0;
ab_t a1;
ab_t a2;
)) {
CO_V(task_a) = co_new(_coroutine_a, (12, 10));
co_resume(CO_V(task_a), CO_V(a0));
co_resume(CO_V(task_a), CO_V(a1));
co_resume(CO_V(task_a), CO_V(a2));
printf("returned value %d %d %d\n", CO_V(a0).a, CO_V(a1).a, CO_V(a2).a);
co_free(CO_V(task_a));
} co_end()
int main(void)
{
co_scheduler_t* scheduler = co_scheduler_new();
co_routine_t* const task = co_new(_coroutine_b, ());
co_schedule(scheduler, task);
co_free(task);
co_scheduler_free(scheduler);
return 0;
}
co_decl_task will declare the interface and the implementation. You can also separate the interface into header file with co_decl and implementation into co_task. In this case, static keyword continues to work to scope the coroutine to file-level visibility. Taking a look at this:
1
static co_decl_task(ab_t, _coroutine_a, (const int a, const int b),
The first parameter is the return type, and then function name, parameters, all feel very natural to C functions. The local variable has to be declared within the private block, that’s the only catch.
To access parameters and local variables, you have to use CO_P / CO_V macro to wrap the access, otherwise it is the same.
Of course, there are a few more catches:
- No variadic parameters;
- No variable length local arrays;
- No void,
()meant for that in parameters, and you can simply omit the return type if you don’t need them.
There is no magic really, just some ugly macros hide away the complexity of allocating parameters / local variables on the heap and such.
There are examples in the repo that shows the usage of co_resume, co_await, co_apply, co_yield, co_decl, co_task, co_decl_task and co_return in varies formats. You can check out more there: https://github.com/liuliu/co
Currently, I have a single-threaded scheduler. However, it is not hard to switch that to a multi-threaded scheduler with the catch that you cannot maintain the dependencies as a linked-list, but rather a tree.
It is a weekend exercise, I don’t expect to maintain this repo going forward. Some form of this will be ported into nnc.
Closing Thoughts
In theory, swapcontext / makecontext can make a much more complex interaction between functions that an extra scheduler object is not needed. For what it’s worth, Protothreads also doesn’t have a central scheduler. But in practice, I found it still miles easier to have a scheduler like what libtask does. Tracking and debugging is much easier with a central scheduler especially if you want to make that multi-thread safe as well.
To train large deep neural network, you need a lot of GPU and a lot of memory. That is why a Titan RTX card cost more than 3 times of a RTX 2080 Ti with just a bit more tensor cores. It has 24GiB memory and that makes a lot of models much easier to train. More memory also means bigger batch size. Many GPU kernels run faster with larger batch size. If somehow we can reduce memory footprint at training time, we can train bigger models, and we can train with larger batch size faster.
There are methods to reduce memory footprints. It is no-brainer nowadays to use fp16 for training. Other than that, many of today’s memory reduction techniques are derivatives of binomial checkpointing, a well-known technique in automatic differentiation community. Specific details need to be considered that cheap operations such as batch normalization or RELU results can be dropped and then recomputed later. The paper suggested a 30% more time required for DNN-tuned binomial checkpointing for roughly 80% reduction in memory usage. In practice, people often see 10% more time with 50% reduction in memory usage thanks to optimizations in forward pass over the years.
In the past a few days, I’ve been experimenting with another type of memory usage reduction technique.
It is common today in operating systems to do something called virtual memory compression. It uses data compression techniques to compress under-utilized pages, and on page fault, to decompress these pages back. These are lossless compressions. It doesn’t make sense to revisit some memory and suddenly an ‘a’ becomes a ‘z’. However, in another world, lossy compression does used to reduce memory usage.
In computer graphics, a full-blown 32-bit texture could take a lot of memory. People exploited more effective texture representation for ages. Formats such as PVRTC or ETC rely on heavy compression schemes (many involve search a space for better representations) to find perceptually similar but much smaller texture representation. For example, PVRTC2 could spend less than 15% memory for visually the same result as a full-blown 32-bit texture. These compression schemes are also very light and predictable to decompress.
There are certain similarities between textures and tensors for convolutional neural networks. They both have spatial dimensions. Convolutional neural networks traditionally have more precisions, but nowadays we are exploring 4-bit or 8-bit tensors for convolutional neural networks too. For a tensor compression algorithm to work in practice, it needs to be fast at both compression and decompression on GPU, and hopefully, has high fidelity to the original.
I’ve devised a very simple, very easy-to-implement adaptive quantization algorithm for this purpose. The past a few days, I’ve been experimenting on ResNet-50 models to confirm its effectiveness.
At batch size 128x4 (4 GPUs, 128 per GPU), the baseline ResNet-50 model trained on ImageNet reached single crop top-1 accuracy 77.6% with 20.97GiB memory allocated across 4 GPUs. The ResNet-50 model with tensor compression trained on ImageNet reached accuracy 75.8% with 6.75GiB memory allocated.
On each feature map, within a 4x4 patch, we find the max value and the min value. With these, we have 4 values {min, max - min) / 3 + min, (max - min) * 2 / 3 + min, max}. Each scalar within that 4x4 patch can be represented with one of the 4 values. Thus, we use 2 bits per scalar. That totals 64 bits per patch, 25% of the original (assuming fp16). This is super easy to implement on GPU, in fact, I am surprised my simple-minded implementation on GPU this fast. It incurs less than 10% runtime cost during training (throughput reduced from 1420 images per second to 1290 images per second).
It is also simple to update the computation graph for tensor compression. For each convolution layer’s output tensor, if it is used during backpropagation, we compress it immediately after its creation in forward pass, and decompress it before its use in backpropagation. If the backpropagation of the convolution layer uses a input tensor, we compress it immediately after its creation in forward pass, and decompress it before its use in the backpropagation. This simple scheme covered all tensors potentially have spatial redundancy.
Is this algorithm useful? Probably not. As long as there are accuracy loss, I am pretty certain no one will use it. At this moment, it is unclear whether 2-bit is too little or this whole scheme inherently doesn’t work. Some more experiments are required to determine whether adaptive quantization is good enough or the spatial redundancy plays a role (by adaptive quantize across feature maps rather than within a feature map). Nevertheless, I’d like to share these early results to help the community determine whether this is a worthy path to explore.
You can find the CUDA implementation of the above adaptive quantization algorithm in: https://github.com/liuliu/ccv/blob/unstable/lib/nnc/cmd/compression/gpu/ccv_nnc_lssc_gpu_ref.cu