Back in late 2012, it was not nearly as obvious as now how long the deep learning AI renaissance was going to last. Alex Krizhevsky has been working on cuda-convnet from code.google.com for over a year, and only then, people started to download the code and to reproduce “CIFAR-10 under 30-minute” with their own GPUs.
History can take many different paths at that point. If Alex & Hinton’s startup hadn’t been sold to Google at that time, if the core technology weren’t invented & patented over 2 decades ago, we may have a better image classification system available for a price. It may be commercially successful: start by licensing its technology and later find consumer market use cases like PageRank and Google. Or it may not be commercially viable, like SIFT and Evolution Robotics a decade ago.
In our universe, history took a different path. While with initial cuda-convnet code release, it was still a lot of work to train ImageNet models, within a year, researchers from Microsoft, Baidu, IBM and Stanford (Google bought Alex & Hinton’s startup) were able to successfully reproduce the work on ImageNet. Yangqing Jia released Caffe and then the cat was out of the box. Anyone with a decent computer can now poke the most powerful image classification models locally. Initially, there are custom non-commercial clauses for the trained models, possibly inherited from the ImageNet dataset. These clauses were dropped relatively quickly in favor of Creative Commons.
This was not the norm in the computer vision community. It was a dark age where algorithms were implemented with proprietary MATLAB software (remember why Ross Girshick’s original R-CNN was so hard to reproduce? The saliency detection algorithm “selective search” it used was implemented with a mix of C plugin and MATLAB code) or closely guarded as the trade secret. Different groups did slight variations of summed-area-table features and boosting algorithms to side-stepping Viola’s face detector patent. Histogram of Gradients (HoG) and Deformable Parts Models (DPM) while great on paper, and the former was the best manual engineered image features by far, never made their way into OpenCV package due to patent concerns (and yes, both were implemented in MATLAB and source available for non-commercial use upon request). Maintainers of OpenCV had to go to great lengths to implement “patent-free” alternatives that simply weren’t as good.
At the pivotal moment of 2013, researchers and engineers from different groups, with different ideologies and commercial considerations, made the choice. They chose openness. Started with the release of code and various models from Caffe and OverFeat, legacy packages that were only maintained by a small group of hobbyists now received corporate sponsorship. Engineers were poured into LuaTorch to fix its issues. Caffe’s author and Theano’s authors were recruited. Python became the preferred language for machine learning, and TensorFlow was released in late 2015.
When YOLO released in 2015, important computer vision tasks that made limited progress during the 2000s, now all have performant and open-source (in no-string-attached way) code that you can run from beefy servers to microcontrollers while handily beating proprietary solutions.
The reason for the openness can certainly be debated as not purely ideology-based. Big corporations such as Google and Facebook have strong incentives to commoditize technologies that are complementary to their core business. They had some successes before: Android from Google and OpenCompute from Facebook were two canonical examples that commoditized the strength of their competitors.
Looking back, it certainly shows. Technology companies that kept their tech stack private faced an uphill battle. Clarifai, MagicLeap, or a slew of AI startups that failed to sell to the big corporations, had a hard time to keep up with the ever evolving open-source counterparts. Even the reasonably isolated Chinese companies (SenseTime, or Face++) have grown to rely on government contracts to keep themselves above the water.
Curiously, in the past decade, deep learning has created trillions of dollars in value and impacted all aspects of our lives, from the smartphones that can automatically enhance your videos and voices, put on a face paint, to dictate messages, search through your photos and recommend better short videos to watch. However, even at the market peak of 2021, no single 100 billion public company was created based on their innovative technology in deep learning. Meanwhile, technology has progressed at breaking-neck speed. The de-facto publication requirement of open code & data access and the emerging facilitators such as paperswithcode.com made introspection and reproduction much easier than the decade before. This is an explicit choice. The alternative is to have slower progress, spending years of graduate student’s time on probing what the papers from others may do, and hoarding the value behind patents.
The impact where a determined 17-year-old can just go to fast.ai, install PyTorch and run state-of-the-art models from their laptop cannot be overstated. Looking at the numbers, there are many more first-time authors from NeurIPS comparing 2021 against 2011. The trio of easy-to-access tutorials, easy-to-access code and easy-to-access data formed the basis for the decade of AI renaissance.
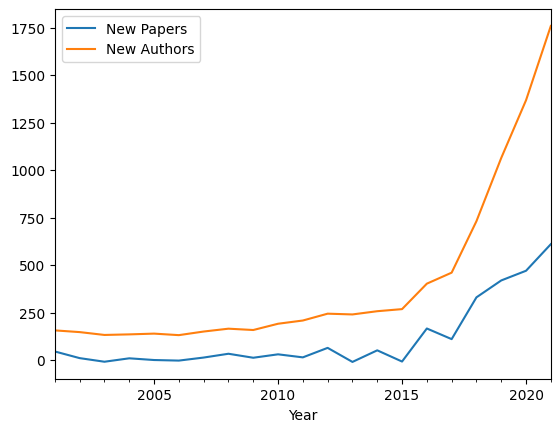
(This plots the derivative of the growth: how many additional papers accepted in NeurIPS per year, and how many new authors appeared in that year)
With how fast the area has progressed, many more practitioners are now more optimistic about when we will reach parity with human intelligence. It would probably be only decades away, rather than centuries as previously thought.
However, more recently, there are certain worrying trends inside the AI community. Models now are bigger and cost millions of dollars to train. While efforts were made with OPT-175B, BLOOM and Stable Diffusion, training these models even with the latest DGX station at home remains challenging. Compared to another novel area NeRF where the models are easier to train on a single GPU, the publications are much more diverse from later. If we cannot effectively reduce the reproduction cost for large models, our progress will be slowed. Areas such as biology and high-energy physics are cautionary tales of what could happen if you can only do cutting-edge research in a very limited number of laboratories around the world.
Epilogue
There are too many people involved to be named in this short essay. Kaldi democratized once a complex speech recognition pipeline. HuggingFace’s first release of BERT models in PyTorch unleashed the collaborative research of pre-trained large language models. OpenAI, with its many faults, still maintains its OpenAI Gym benchmark and the set of implemented reinforcement learning algorithms under Spinning Up. Leela Chess Zero reimplemented AlphaGo (and later AlphaZero). Various open-source protein folding implementations forced DeepMind to release AlphaFold. Not to mention dataset and benchmark works by many researchers to bootstrap Big Data centric learning algorithms to begin with.