“Use-faced” computing: any computing that needs to happen in the tight loop of users interacting with each other or themselves. By this definition, most business insight generations, log processing, server health stats, data reprocessing for cold storage, automated trading, and automatic surveillance analysis are not user-faced computing. Conversely, when you send a message to another user, every step in this process counts as user-faced computing.
Many people have the misconception that most user-faced computing has shifted to the cloud (remote servers) in recent years.
Messaging, arguably one of the more “even” interactions (i.e., typing/encrypting one message involves very little client computing), still spends very little computing on the server computing. Signal, an open messaging platform, has calculated its server computing costs at approximately 2.9 million dollars per year, equating to about $0.058 per user per year, or roughly 10 vCPU hours per user. User time spent, while not revealed or collected, should far exceed this number (both Meta & Snap report time spent around 0.5 hours per day per user).
There have been many indications that most user-faced computing occurs primarily on the client-side. Most personal devices in the past 15 years have included hardware-level support for video decoding/encoding. However, only recently (in the past 5 years) have major video providers like YouTube started switching to their own video acceleration chips.
Efforts to shift this balance have been made. Video games, which demand significant client computing, have been attempting to move to the cloud since OnLive’s debut in 2008. More substantial efforts followed, including NVIDIA GeForce NOW, Xbox Cloud Gaming, Google Stadia, and Unity Parsec, to name a few. However, few have succeeded.
Conversely, the transition of storage to the cloud has been phenomenally successful. Many companies and services have thrived by moving what we store locally to remote servers: Dropbox, Spotify, YouTube, iCloud services, Google Photos. Today, operating your own local storage box is a niche activity (e.g., r/DataHoarder) outside the mainstream.
The change is already under way.
ChatGPT, the most successful generative AI product to date, demonstrates a significant imbalance in user-faced computing: to complete each query, it requires approximately 1 to 3 seconds of dedicated GPU time on 8-H100 machines. Google doesn’t publish their numbers on search, but it is likely to be 1 or 2 orders of magnitude smaller in comparison.
This puts an immense pressure to secure computing-heavy servers to meet the needs of generative AI, in terms of text/image/video generation inferences. So far, companies are often limited by how much server-computing resources they can secure to support their user growth.
Is this a phase change? Could it be a temporary crunch? Why has the storage transition been so successful while the computing shift lags behind?
A closer analysis of the storage transition reveals it is fairly straightforward. While storage capacity continues to grow at a steady rate (2008, 1.5TB; 2023, 20TB; approximately 20% per year), the form factor and price haven’t changed significantly (2008, $100 per terabyte; 2023, $25 per terabyte; approximately 10% per year). The shift of personal devices to SSDs further exacerbated this issue: in 2008, $100 per terabyte HDD; in 2023, $80 per terabyte SSD.
Cost-wise, moving to the cloud offers at most modest savings. However, the inherent redundancy in data provides 3 to 4 orders of magnitude in savings, making cloud storage more appealing in other aspects. In the early 2000s, devices like the iPod were frequently advertised for their large storage capacity, capable of holding thousands of songs. These are examples of redundant storage easily shared among users. The fact that many users consume the same content makes cloud storage economically efficient. Other minor improvements, such as a 10x increase in household bandwidth and a 100x increase in mobile bandwidth, render the bandwidth benefits of local storage negligible.
With user-faced computing contemplating a potential move to the cloud, the advantages are clear. The computing requirements for generative AI, especially for high-quality results, are not easily met in portable form factors. There are also redundancies that can be exploited. KV cache, a straightforward optimization for large language model inference, eliminates redundant computing between token generations. vLLM takes this further by sharing KV caches between batches. While not widely deployed yet, it is conceivable that KV cache could be shared between different users and sessions, potentially leading to a 10x efficiency improvement (though this raises its own security concerns, such as the risk of timing attacks on LLM’s KV cache potentially recovering previous conversations or conversations between different users).
Another advantage of moving user-faced computing to the cloud is data efficiency. Like video games, generative AI models require substantial data payloads to function. When user-faced computing shifts to the cloud, data transfer between the server and client becomes unnecessary. This enables the instant satisfaction that most cloud gaming platforms promise. However, it remains unclear whether new experiences can be enabled by delta-patching the existing model or whether transmitting a new model is necessary.
Will this phase change in user-faced computing finally occur? What should we watch for?
First, if this phase change materializes, we could see a 1 to 2 orders of magnitude increase in server-side computing capacity. This would make what NVIDIA/AMD ships today seem insignificant in 5 years.
Second, the success of this transition is not guaranteed. It is not as straightforward as the storage transition to the cloud. There have been previous failures (e.g., cloud gaming). It depends on several factors: 1. Will client computing power/efficiency continue to grow at approximately 50%, leading to nearly a 10x increase in local computing power in 5 years? 2. Will we see an acceleration in available RAM/storage locally to support large models? 3. Would there be a winner model that serves as the true foundation for other model adapters to adapt?
Third, resistance to this phase change also comes from within. The cost of acquiring computing hardware impacts both pricing and availability. It is unclear whether the economics will be viable without addressing these price and availability gaps.
With broader access to Llama, Alpaca, ChatGLM, and Dolly available on ordinary consumer-level hardware, we have entered a new phase where every technology-literate person can access GPT-3 level perplexity language models, which also inherit all the shortcomings of GPT-3 level models. These models hallucinate a lot, lack the knowledge of their more parameter-heavy counterparts, and are not nearly as reliable. However, with the right prompt, they are just effective enough at generating marketing copies, manipulating societal opinions, and making convincing arguments on either side as we are prompting.
If GPT-4 is more aligned, trained with more data, has less hallucination, and is more knowledgeable, it would perplex me why we would not want to provide as broad access as possible, as soon as possible, and explore as many avenues to achieve that as possible, including releasing weights and model details to many partners or the general public, to ensure timely and broad access with a fairer and more knowledgeable model.
The problem is that we are not in the Pre-GPT3 world, where only select parties had access to models as powerful as GPT-3, while we were making theoretical arguments weighing the downsides versus the upsides. All that stayed in theory a few years ago: how GPT-generated content would affect our content consumption, influence our opinions, search rankings, or be weaponized against individuals to induce anxiety and stress are all happening now. This begs that we release updated technology as soon as possible, making it as widely available as possible.
There could be some credible objections to this line of thinking. We will discuss them one by one.
A More Potent Threat
There could be new threats enabled by GPT-4 because it is more potent. We have made strides in areas we knew to be problematic: hallucinations, biases, and emotional manipulations. There could be surfaces that were previously unknown and only made possible with more potent models. The challenge here is to identify these cases rather than theorize. While we do not know about the unknown, the known harms introduced by Pre-GPT4 models, particularly regarding knowledge hallucination and content pollution, are real and ongoing. Evaluating ongoing harms against unknown threat surfaces is difficult. It is a challenging moral choice because even intentional immobility could potentially cause more harm.
Unmanageable Releases
Once a model is out in the public, it is difficult to “unpublish” or “upgrade.” Having one entity manage the release and access would ensure that, at critical times, we have the option to roll back. However, let’s take a step back and think about the kind of threats or harms we are trying to protect against by rolling back. Are we going to suddenly have a much less aligned model that can cause more extraordinary harm than the existing one? In other words, when we update the model, are we navigating through a rough surface where there are unintentional pockets the model can fall into, making it worse-behaving; or are we navigating through a smoother surface where the model progressively becomes more aligned?
The Mix-and-Match of the Models
While there might be only one base model, there could be several LEGO pieces (or guardrails) to ensure the model is aligned with our expectations: a step to insert watermarks so the content is traceable or a post-filter to ensure bigoted content is blocked at the last step. Broader distributed access would mean that some parties can turn off these guardrails if needed. An advanced model, such as GPT-4 without guardrails, could mean enhanced harms because it is harder to detect and neutralize the threat it poses.
When discussing these objections, we must be clear about the types of societal harms we aim to prevent. Are we trying to stop bad actors from using LLMs to augment their abilities, or are we trying to minimize harms induced by misuse? Failing to distinguish between these cases will only muddy the waters without providing any benefits. It is important to remember that we do have releases of quite a few GPT-3 level models now that are easier to hallucinate, are indistinguishable with humans for short-and-concise conversations, and can certainly be used by someone determined to cause greater harm.
For bad actors, Pre-GPT4 models are already capable. These models can be fine-tuned easily, have source code available in various forms, and can be embedded almost anywhere. When deployed at scale for the purpose of influencing campaigns or scams, it is unclear how their effectiveness compares to existing methods. At this point, it is speculative how GPT4 models compare to Pre-GPT4 models. My educated guess is that there would be an order of magnitude improvement for the first case and much less (double-digit percentage) for the latter.
For misuse, the harm is immediate and present. An unsuspecting student using Pre-GPT4 models to ask for clarifications on questions could receive misleading yet confident answers. In these cases, having the updated, more powerful model readily available would prevent more harm.
The Unmitigable Risks
Given the prevalence of open-source GPT3-level models, I would argue that we are already deep in the valley of unmitigable risks. Counterintuitively, taking slow, measured steps might shorten the distance traveled in the valley, but sprinting in a roughly-right direction would prove to be the shortest in terms of time spent. If we treat the current situation as one of unmitigable risks, for the betterment of humanity, we should seek the broadest access to the latest aligned model at any cost.
Every year, we have a new iPhone that claims to be faster and better in every way. And yes, these new computer vision models and new image sensors can exercise the phone as hard as they can. However, you could already take good pictures on an iPhone 10 years ago. These are incremental improvements.
These incremental asks only deserve incremental improvements. Once in a few years, there are programs where even on the best of our computing devices they can be barely usable. But these new programs with newly enabled scenarios are so great that people are willing to suffer through.
Last time this happened was the deep neural networks, and the time before that, was the 3D graphics. I believe this is the 3rd time. In fact, I am so convinced that I built an app to prove the point.
In the past 3 weeks, I built an app that can summon images by casting a few spells, and then editing it to the way you liked. It took a minute to summon the picture on the latest and greatest iPhone 14 Pro, uses about 2GiB in-app memory, and requires you to download about 2GiB data to get started. Even though the app itself is rock solid, given these requirements, I would probably call it barely usable.
Even if it took a minute to paint one image, now my Camera Roll is filled with drawings from this app. It is an addictive endeavor. More than that, I am getting better at it. If the face is cropped, now I know how to use the inpainting model to fill it in. If the inpainting model doesn’t do its job, you can always use a paint brush to paint it over and do an image-to-image generation again focused in that area.
Now the cat is out of the box, let’s talk about how.
It turns out, to run Stable Diffusion on an iPhone is easier than I thought, and I probably left 50% performance on the table still. It is just a ton of details. The main challenge is to run the app on the 6GiB RAM iPhone devices. 6GiB sounds a lot, but iOS will start to kill your app if you use more than 2.8GiB on a 6GiB device, and more than 2GiB on a 4GiB device.
The original Stable Diffusion open-source version cannot run on a 8GiB card, and these are 8GiB usable space. But before that, let’s get to some basics. How much memory exactly does the Stable Diffusion model need for inference?
The model has 4 parts: a text encoder that generates text feature vectors to guide the image generation. An optional image encoder to encode image into latent space (for image-to-image generation). A denoiser model that slowly denoise out a latent representation of an image from noise. An image decoder to decode the image from that latent representation. The 1st, 2nd, and 4th models need to run once during inference. They are relatively cheap (around 1GiB max). The denoiser model’s weights occupy 3.2GiB (in full floating-point) of the original 4.2GiB model weights. It also needs to run multiple times per execution, so we want to keep it in RAM longer.
Then, why originally Stable Diffusion model requires close to 10GiB to run for a single image inference? Besides the other weights we didn’t unload (about 1GiB in full floating point), there are tons of intermediate allocations required. Between the single input (2x4x64x64) and single output (2x4x64x64), there are many layer outputs. Not all layer outputs can be immediately reused next. Some of these, due to the network structures, have to be kept around to be used later (residual networks). Besides that, PyTorch uses NVIDIA CUDNN and CUBLAS libraries. These libraries kept their own scratch space as well. Since the publication, many optimizations have been done on the PyTorch stable diffusion model to bring the memory usage down so it can be run with as little as 4GiB cards.
That’s still a little bit more than what we can afford. But I will focus on Apple hardware and optimization now.
The 3.2GiB, or 1.6GiB in half floating-point, is the starting point we are working with. We have around 500MiB space to work with if we don’t want to get near where Apple’s OOM killer might kill us.
The first question, what exactly is the size of each intermediate output?
It turns out that most of them are relatively small, in a range lower than 6MiB each (2x320x64x64). The framework I use (s4nnc) does a reasonable job of bin-packing them into somewhere less than 50MiB total accounting for reuses etc. Then there is a particularly interesting one. Denoiser has a self-attention mechanism with its own image latent representation as input. During self-attention computation, there is a batched matrix of size (16x4096x4096). That, if not obvious, is about 500MiB in half floating-point (FP16). Later, we applied softmax against this matrix. That’s another 500MiB in FP16. A careful softmax implementation can be done “inplace”, meaning it can rewrite its input safely without corruption. Luckily, both Apple and NVIDIA low-level libraries provided inplace softmax implementation. Unluckily, higher level libraries such as PyTorch didn’t expose that.
So, it is tight, but it sounds like we can get it done somewhere around 550MiB + 1.6GiB?
On Apple hardware, a popular choice to implement neural network backend is to use the MPSGraph framework. It is a pretty fancy framework that sports a static computation graph construction mechanism (or otherwise known as “TensorFlow”). People liked it because it is reasonably ergonomic and performant (have all the conveniences such as the broadcast semantics). PyTorch’s new M1 support has a large chunk of code implemented with MPSGraph.
For the first pass, I implemented all neural network operations with MPSGraph. It uses about 6GiB (!!!) at peak with FP16 precision. What’s going on?
First, let me be honest, I don’t exactly use MPSGraph as it is expected (a.k.a., the TensorFlow way). MPSGraph probably expects you to encode the whole computation graph and then feed it input / output tensors. It then handles internal allocations for you, and lets you submit the whole graph for execution. The way I use MPSGraph is much like how PyTorch does it: as an op execution engine. Thus, for inference, there are many compiled MPSGraphExecutable gets executed on a Metal command queue. Because each of these may hold some intermediate allocations. If you submit all of them at once, they will all hold the allocations at submission time until it finishes the execution.
A simple way to solve this is to pace the submission. There is no reason to submit them all at once, and in fact, Metal has a limit of 64 concurrent submissions per queue. I paced the submission to 8 ops at a time, and that drives the peak memory down to 4GiB.
That is still 2 GiB more than what we can afford on an iPhone. What gives? Before that, more background stories: when compute self-attentions with CUDA, a common trick, as implemented in original Stable Diffusion code, is to use permutation rather than transposes (for more about what I mean, please read Transformers from the Scratch). This helps because CUBLAS can deal with permuted strided tensors directly, avoiding one dedicated memory traffic to transpose a tensor.
But for MPSGraph, there is no strided tensor support. Thus, a permuted tensor will be transposed anyway internally, and that requires one more intermediate allocation. By transposing explicitly, the allocation will be handled by the higher-level layer, avoiding the inefficiency inside MPSGraph. This trick drives the memory usage close to 3GiB now.
1GiB to go, and more back stories! Before MPSGraph, there was Metal Performance Shaders. These are a collection of fixed Metal primitives for some neural network operations. You can think of MPSGraph as this more shining, just-in-time compiled shaders while Metal Performance Shaders are the older, but more reliable alternative.
It turns out that MPSGraph as of iOS 16.0 doesn’t make the optimal allocation decision for softmax. Even if both the input and output tensors point to the same data, MPSGraph will allocate an extra output tensor and then copy the result over to the place we pointed it to. This is not exactly memory sensitive due to the 500MiB tensor we mentioned earlier. Using the Metal Performance Shaders alternative does exactly what we want and this brings memory usage down to 2.5GiB without any performance regression.
The same story happened to the GEMM kernel of MPSGraph: some GEMM require transposes internally, and these require internal allocations (rather than just use the strided tensor for multiplication directly like what GEMM from Metal Performance Shaders or CUBLAS did. However, curiously, at the MLIR layer, GEMM inside MPSGraph seems indeed to support transpose parameters (without additional allocation) like most other GEMM kernels). Moving these transposes out explicitly doesn’t help either because transposes are not “inplace” ops for the higher-level layer, so this extra allocation is unavoidable for that particular 500MiB size tensor. By switching to Metal Performance Shaders, we reclaimed another 500MiB with about 1% performance loss. There, we finally arrived at the 2GiB size we strived for earlier.
There are still a bunch of performances I left on the table. I never switched to ANE while finally getting some sense about how (it requires a specific convolution input shape / stride, and for these, you can enable the mysterious OptimizationLevel1 flag). Using Int8 for convolution seems to be a safe bet (I looked at the magnitude of these weights, none exceeding the magic 6) and can save both the model size and the memory usage about 200MiB more. I should move the attention module to a custom made one, much like FlashAttention or XFormer on the CUDA side. These combined, probably can reduce runtime by 30% and memory usage by about 15%. Well, for another day.
You can download Draw Things today at https://draw.nnc.ai/
Here are some related links on this topic:
-
How to Draw Anything, this is the most influential piece to me on this topic early on, and I point everyone who liked this topic to this post. It describes one workflow where text-to-image models can be more than a party trick. It is a real productivity tool (since then, there are more alternative workflows popping up, people are still figuring this out).
-
Maple Diffusion, while I am working on swift-diffusion, there is an concurrent effort by @madebyollin to implement stable diffusion in MPSGraph directly. I learned from this experiment that NHWC layout might be more fruitful on M1 hardware, and switched accordingly.
Reinforcement learning algorithms are ridiculously fragile. Older deep Q-learning algorithms may or may not train just with a different seed. Newer algorithms such as PPO and SAC are much more stable. Well-configured ones can train on a wide range of tasks with same / similar hyper-parameters. Because of that, these algorithms are now used more and more in real-world settings, rather than just a research interest.
To implement PPO and SAC from scratch correctly, however, can still be challenging. The wonderful blog post The 37 Implementation Details of Proximal Policy Optimization covered many aspects of it. Tianshou’s training book also contains many gems. The problem, as 37 Implementation Details pointed out, can be traced to the fact that many libraries have logics distributed to different places, which makes it harder to understand what tricks the author applied to reach a certain score.
I am going to highlight a few more implementation details here that are not covered in 37 Implementation Details. Hopefully this would help other practitioners in RL to implement these algorithms.
Action Scaling and Clipping
37 Implementation Details mentioned action clipping, and casually said that “the original unclipped action is stored as part of the episodic data”. What it means is that when compute logarithmic probabilities on the distribution, we should use the unclipped action value. Using the clipped action value would make the training unstable, causing NaNs in the middle of a training, due to the clipped action value drifting too far from the centroid.
While clipping to the action range directly would work for simpler cases such as InvertedPendulum or Ant, for Humanoid, it is better to clip to range [-1, 1] and then scale to the action range. The latter approach showed to be more stable on all MuJoCo tasks.
Clipping Conditional Sigma
SAC, when trained with continuous action space such as MuJoCo tasks, need to sample from a Gaussian distribution with conditional sigma. The conditional sigma is derived from the input and conveniently shares the same network as the action. It turns out to be helpful to constrain the range of sigma when doing action sampling. This helps to avoid NaN when sigma is too big. A common choice is between [-20, 2]. Did you notice the -20 on the lower bound? That’s because we will apply exp on the sigma value (thus, the network produced sigmas are really the “log sigmas”), hence reflected on the range.
Updates to Reward Normalization (or “Reward Scaling”)
Depending on your implementations, you may collect data from the vectorized environments into many micro-batches, which sometimes would be easier to treat truncated / terminated returns differently. Reward normalization collects statistics (standard deviation) from returns in these micro-batches. The statistics will also be used to normalize subsequent returns. It is recommended to update the statistics on a per batch basis. Thus, for the current batch, always use the statistics calibrated from the previous batch. Keeping an updated statistics and using that directly in the current batch can cause further instabilities during the training.
Observation Clipping
If no observation normalization, clipping is not needed. After normalization however, clipping can help to avoid sharp changes in losses, thus, making the training smoother.
Logarithmic Probability (Entropy) on Gaussian and Corrected for Tanh Squashing
Logarithmic probability is computed element-wise. This is not a problem for PPO because there is no correction term and it is easy to balance its actor losses (only two terms, one from the “entropy” (logarithmic probability), one to regularize sampling sigma). For SAC, it is not so easy. Entropies are corrected for tanh squashing, and mixed with rewards, resulting in a target / loss with 3 to 4 terms. This is especially important if you implement the log_prob function yourselves.
It seems summing up along the feature dimension matches the SAC paper. Mismatching this (i.e. averaging for log_prob but summing up for correction terms) can cause sudden spikes in critic / actor losses and harder to recover from it.
Reward Scaling
This is different from “reward normalization” in PPO. For SAC, since it computes the current target value with n-step rewards + future value + action entropy. The reward scaling here refers to applying coefficient to the n-step rewards to balance between critics’ estimation and the near-term reward. This is important for SAC because of the entropy term’s scale again. Higher reward scaling results in more exploitation while lower reward scaling results in more exploration.
Back in late 2012, it was not nearly as obvious as now how long the deep learning AI renaissance was going to last. Alex Krizhevsky has been working on cuda-convnet from code.google.com for over a year, and only then, people started to download the code and to reproduce “CIFAR-10 under 30-minute” with their own GPUs.
History can take many different paths at that point. If Alex & Hinton’s startup hadn’t been sold to Google at that time, if the core technology weren’t invented & patented over 2 decades ago, we may have a better image classification system available for a price. It may be commercially successful: start by licensing its technology and later find consumer market use cases like PageRank and Google. Or it may not be commercially viable, like SIFT and Evolution Robotics a decade ago.
In our universe, history took a different path. While with initial cuda-convnet code release, it was still a lot of work to train ImageNet models, within a year, researchers from Microsoft, Baidu, IBM and Stanford (Google bought Alex & Hinton’s startup) were able to successfully reproduce the work on ImageNet. Yangqing Jia released Caffe and then the cat was out of the box. Anyone with a decent computer can now poke the most powerful image classification models locally. Initially, there are custom non-commercial clauses for the trained models, possibly inherited from the ImageNet dataset. These clauses were dropped relatively quickly in favor of Creative Commons.
This was not the norm in the computer vision community. It was a dark age where algorithms were implemented with proprietary MATLAB software (remember why Ross Girshick’s original R-CNN was so hard to reproduce? The saliency detection algorithm “selective search” it used was implemented with a mix of C plugin and MATLAB code) or closely guarded as the trade secret. Different groups did slight variations of summed-area-table features and boosting algorithms to side-stepping Viola’s face detector patent. Histogram of Gradients (HoG) and Deformable Parts Models (DPM) while great on paper, and the former was the best manual engineered image features by far, never made their way into OpenCV package due to patent concerns (and yes, both were implemented in MATLAB and source available for non-commercial use upon request). Maintainers of OpenCV had to go to great lengths to implement “patent-free” alternatives that simply weren’t as good.
At the pivotal moment of 2013, researchers and engineers from different groups, with different ideologies and commercial considerations, made the choice. They chose openness. Started with the release of code and various models from Caffe and OverFeat, legacy packages that were only maintained by a small group of hobbyists now received corporate sponsorship. Engineers were poured into LuaTorch to fix its issues. Caffe’s author and Theano’s authors were recruited. Python became the preferred language for machine learning, and TensorFlow was released in late 2015.
When YOLO released in 2015, important computer vision tasks that made limited progress during the 2000s, now all have performant and open-source (in no-string-attached way) code that you can run from beefy servers to microcontrollers while handily beating proprietary solutions.
The reason for the openness can certainly be debated as not purely ideology-based. Big corporations such as Google and Facebook have strong incentives to commoditize technologies that are complementary to their core business. They had some successes before: Android from Google and OpenCompute from Facebook were two canonical examples that commoditized the strength of their competitors.
Looking back, it certainly shows. Technology companies that kept their tech stack private faced an uphill battle. Clarifai, MagicLeap, or a slew of AI startups that failed to sell to the big corporations, had a hard time to keep up with the ever evolving open-source counterparts. Even the reasonably isolated Chinese companies (SenseTime, or Face++) have grown to rely on government contracts to keep themselves above the water.
Curiously, in the past decade, deep learning has created trillions of dollars in value and impacted all aspects of our lives, from the smartphones that can automatically enhance your videos and voices, put on a face paint, to dictate messages, search through your photos and recommend better short videos to watch. However, even at the market peak of 2021, no single 100 billion public company was created based on their innovative technology in deep learning. Meanwhile, technology has progressed at breaking-neck speed. The de-facto publication requirement of open code & data access and the emerging facilitators such as paperswithcode.com made introspection and reproduction much easier than the decade before. This is an explicit choice. The alternative is to have slower progress, spending years of graduate student’s time on probing what the papers from others may do, and hoarding the value behind patents.
The impact where a determined 17-year-old can just go to fast.ai, install PyTorch and run state-of-the-art models from their laptop cannot be overstated. Looking at the numbers, there are many more first-time authors from NeurIPS comparing 2021 against 2011. The trio of easy-to-access tutorials, easy-to-access code and easy-to-access data formed the basis for the decade of AI renaissance.
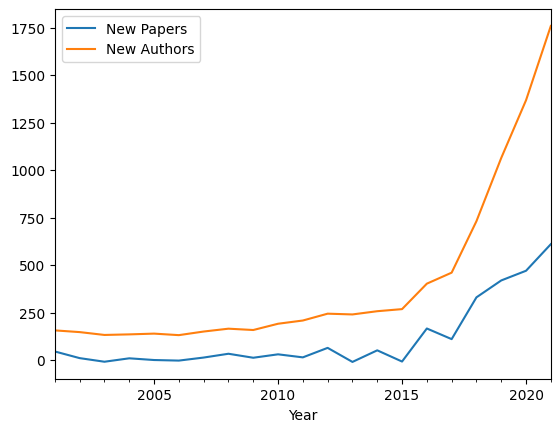
(This plots the derivative of the growth: how many additional papers accepted in NeurIPS per year, and how many new authors appeared in that year)
With how fast the area has progressed, many more practitioners are now more optimistic about when we will reach parity with human intelligence. It would probably be only decades away, rather than centuries as previously thought.
However, more recently, there are certain worrying trends inside the AI community. Models now are bigger and cost millions of dollars to train. While efforts were made with OPT-175B, BLOOM and Stable Diffusion, training these models even with the latest DGX station at home remains challenging. Compared to another novel area NeRF where the models are easier to train on a single GPU, the publications are much more diverse from later. If we cannot effectively reduce the reproduction cost for large models, our progress will be slowed. Areas such as biology and high-energy physics are cautionary tales of what could happen if you can only do cutting-edge research in a very limited number of laboratories around the world.
Epilogue
There are too many people involved to be named in this short essay. Kaldi democratized once a complex speech recognition pipeline. HuggingFace’s first release of BERT models in PyTorch unleashed the collaborative research of pre-trained large language models. OpenAI, with its many faults, still maintains its OpenAI Gym benchmark and the set of implemented reinforcement learning algorithms under Spinning Up. Leela Chess Zero reimplemented AlphaGo (and later AlphaZero). Various open-source protein folding implementations forced DeepMind to release AlphaFold. Not to mention dataset and benchmark works by many researchers to bootstrap Big Data centric learning algorithms to begin with.
I did the Underactuated Robotics course at the beginning of this year (for anyone hasn’t, highly recommended! https://underactuated.mit.edu/). One thing interesting to watch is to see how Russ opened the notebook, did the computation instanously, and then spent a few seconds to a minute to generate the animated illustrations.
If you previously Googled about how to show animations in a Jupyter notebook, you probably know what I was talking about. There are two documented ways: 1. sending image display messages to the notebook and rendering the image again and again. There is no control over frame rate, and the re-rendering in the notebook can cause stutters and flashs. 2. rendering the animation into video and only sending the whole to the notebook when it is done. The animation will be smooth, you can also play the video back and forth. However, during the rendering, you have to wait. That is what Russ complained about repeatedly during the course.
This is an interest to me now because I want to build physical models with the amazing MuJoCo library, and it became a headache to view the UI over KVM from my workstation to the laptop (don’t ask why I don’t do this on my laptop directly, long story and weird setup). What if I can write the model in a Jupyter notebook and play with it from the notebook directly? After a few days, well, you can see it now:
I first learned motion-jpeg from the TinyPilot project. It is a space-wise inefficient, but otherwise fast and easy to implement low-latency video streaming protocol. The best part: it is supported universally in all browsers, and over HTTP protocol. The format is dead simple: we reply with the content type as “x-mixed-replace” and a boundary identifier, then just stuff the connection with JPEG images one-by-one. This worked surprisingly well over the local network. No wonder why many cheap webcams, without a better H264 hardware encoder, use motion jpeg as their streaming protocol too.
After sorting out the streaming protocol, what if we can make this interactive? Nowadays, this is as simple as opening a web-socket and passing a few JSON messages over.
With a day of coding, I can now run MuJoCo’s simulate app inside a web browser, not bad!
To integrate with the notebook, there are a few minor, but important usability issues to sort out.
First, how do we know which host we should connect to? Remember, all code in the Jupyter notebook runs on the server, while it can launch a shadow HTTP server without any problems, we need to know if the notebook was opened from 127.0.0.1 or x-1840-bbde.us-west-2.amazonaws.com. Luckily, we can send Javascript to create the img tag, thus, fetching the window.location.hostname directly from the notebook webpage.
Second, how do we know when to launch a HTTP server? This could be maintained globally (i.e., only one HTTP server per notebook), although you probably want this to end as soon as the cell execution ends. If you control the notebook kernel implementation like I do, insert some cell local variables to help would be a good solution. Otherwise, with IPython, you have to get the current execution count (through IPython.Application.instance().kernel.execution_count) to implement poor-person’s cell local variables. It guarantees only one HTTP server would be created per cell, and you can decide whether you want to destroy the HTTP server created by the previous cell, or just keep it running.
With all these tricks, I now can run the control loop for RL Gym and render the view in the notebook smoothly:
I am pretty happy with it now. If there is one thing I’d like to improve, probably at the end of cell execution, I would render all the jpeg frames into a video and embed them into the notebook through the video data attribute. That will keep the notebook self-contained and can render properly if you push it to GitHub or other places that can render the notebook offline.
Once for a while, we asked questions like: what can we do with more computations? When we asked that question in 2010, CUDA came along and Jesen Huang gifted everyone under the sun a GTX 980 or GTX Titan in search of problems beyond graphics that these wonderful computation workhorses can help.
Then suddenly, we found out that we can not only solve simulation problems (3D graphics, physics emulation, weather forecast etc.), but also perception problems with 100x more computations. That started the gold rush of deep learning.
Fast-forward to today, as deep learning makes great advances in perception and understanding, the focus moved from pure computations to interconnects and memory. We can do really interesting things now with the computations available today. What can we do, if there are another 100x more computations available?
Put it more blatantly, I am not interested in supercomputers in data centers to be 100x faster. What if a mobile phone, a laptop, or a Raspberry Pi, can carry 100x more computations in the similar envelope? What can we do with that?
To answer that question, we need to turn our eyes from the virtual world back to our physical world. Because dynamics in the physical world are complex, for many years, we built machines with ruthless simplifications. We built heavy cranes to balance out heavy things we are going to lift. Even our most-advanced robotic arms, often have heavy base such that the dynamics can be affine to the control force. Often than not, humans are in the loop to control these dynamics, such as early airplanes, or F1 racing cars.
That’s why the machines we built today mostly have pretty straightforward dynamics. Even with microcontrollers, our jet-fighters or quad-copters actually have pretty simple dynamics control. Only recently, Boston Dynamics started to build machines with whole-body dynamics in mind and actually have sophisticated dynamics.
Now, imagine a world where every machine is much more nimble, more biological-like, because we don’t need to simplify the system dynamics, but to leverage them. To get there, we need to do much more computations.
To control a dynamics system, we normally need to solve optimization problems with hundreds to thousands of variables. These are not crazy numbers, our computers today can solve eigenvalues of a matrix on the rank of thousands pretty easily. The trick is to do this fast. An active control applied at 1000Hz is much more stable than ones at 10Hz. That means do these numerical integrations, inverting matrices, all under 1 millisecond. For this, we need to do much more computations in 1 millisecond than what we can today.
If we are careful, we will plan our gifted 100x computations more strategically. We will work on anything that reduces computation latency, such as sharing memory between CPUs and GPUs. We will mainstream critical works such as PREEMPT_RT to the Linux kernel. We will reduce the number of ECUs so it is easier to compute whole-body dynamics with one beefier computer. We will make our software / hardware packages more easy-to-use; it will scale from small robot vacuums to biggest cranes.
During our first 100x leap, we solved graphics. With our next 100x leap, we solved simulation and perception. Now it is the time to do another 100x leap, and to solve dynamics. I am convinced this is the only way to build machines as efficient as their biological counterparts. And these more dynamic, more biological-like machines will be our answer to be sustainable, greener, where we can build more with less.
There are three things in the past decade that I am not only wrong once about, but actively being wrong while the situation is evolving. Introspecting how that happened would serve as a useful guide for the future.
Cryptocurrencies
I’ve been exposed to cryptocurrencies, particularly Bitcoin pretty early on, somewhere around 2009 on Hacker News. I’ve run the software at that time (weirdly, on a Windows machine). However, the idea of Austria-doctrine based currency sounded absurd to me. If you cannot control the money supply, how do you reward productivity improvements? Not to mention it also sounded otherworldly this is going to fly with regulators with its money-laundry potential.
Fast-forward today, these concerns are all true, but it doesn’t matter.
Covid-19
One day in February 2020, when walking with a friend, I told him that I thought the Covid-19 was almost over: CDC didn’t report any new cases for a couple of weeks, it all seemed under-control. In March 2020, everything seemed real, but I was optimistic: the worst-case, that is, we didn’t do a damn thing, this thing probably was going to fade away in a year or two. Given that we were doing something, probably a couple of months at most?
Fast-forward today, the end is near after 2 and half years. But the world is not functioning as it was before.
2022 Russian Invasion of Ukraine
Feb 22th, 2022, after Putin announced his recognition of Donetsk and Luhansk as independent regions, I told a friend: it was probably the end of the 8-year war, now there would be a long political battle for Ukrainians.
Fast-forward only 8 days later, we are on the verge of World War 3.
What’s wrong? Why at that time, I seemed unable to grasp the significance of these events even when everything was presented?
For a very long time (really, since I was twelve), I loved to read non-fictions. Unsurprisingly, many of these non-fictions discussed people, companies or events that happened in modern times. These books helped me to shape my world views. They also turned out to be very helpful to predict near-future events.
However, non-fictions presents a very short slice of modern history. A snapshot is static. With many of these snapshots, a static world view was built. A static world view is great locally: easy to understand, and easy to predict. But it is terrible for once-in-a-life-time events.
Equipped with modern economics theory, it is easy to see why cryptocurrencies cannot work. But if history is any guide, this is simply a different group of bankers trying to issue private money again. A fixed-supply system indeed worked a hundred years ago prior to WW1. Many central banks who control our money-supply today were privately-owned a century ago. Cryptocurrency folks will try to be the new central banks of our time. They might fail. But at that point, it is less about sound economics theory, but more about politics and excitement. The device itself can be modified to fit whatever utilities and theories we see suit.
A pandemic is not a linear event. No, I am not talking about infection modeling. China’s successful control of SARS in the beginning of this century was an anomaly, not the rule. Once the containment failed, the duration difference between doing a good job and doing a bad job diminished. The virus will take its course to run out. At that point, vaccines and treatments are wonderful things to reduce fatalities, but not to reduce the length of the suffering collectively. After a century, we still cannot meaningfully reduce the length of a pandemic.
Russia’s invasion is a major violation of post WW2 international order. An invasion to a sovereign nation without provocation, not to mention its casually threatening with nuclear arms is unthinkable if all the reference points are from the past 30 years.
But Putin’s talk, with its nationalistic pride, a blame on Soviet Union for Russian’s suffering, can be rooted clearly back to Peter the Great.
Many people now flocked to compare what happened in Ukraine to what happened prior to WW2. I am not so certain. For one, Germany, while suffering from WW1, was a country on the rise. The similarity stopped at personal ambition, and the nationalism running high in that country.
The only way to model a dynamic world, is to read more on history, much much more than what I was doing before. Although I am not sure where to start.
What will happen next? It is anyone’s guess. I would humbly suggest looking over WW2 and trying to find relevant examples before that. Maybe somewhere about 200 years ago.
After Elon’s announcement of the Tesla Bot [1], many people mocked the silly on-stage presentation and joked about the forever Level-5 Tesla Autopilot. The last time when humanoid robots caught my eye was the Honda Asimo, when I was a kid. I saved money to buy Robosapien the toy because that was the only bipedal humanoid robot toy available.
A decade passed, and the world has given us videos such as Atlas from Boston Dynamics [2]. Where are we at with the dream of humanoid robots? Can the Tesla Bot be delivered to happy customers in a reasonable time frame (< 5 years)? And the most crucial question: what commercial values do bipedal robots have now?
By no means of an expert, I set out to do some research to understand the scope of the problem, and the potential answers.
Why
Besides the obvious satisfaction of seeing a man-made object doing the most human-like behavior: walking, there are many more reasons why we need bipedal robots. It is also hard to distinguish whether these are practical reasons, or because the technology is cool, and we are trying to retrofit a reason behind it.
The most compelling answer I see so far, reasoned like this: even in the United States, where building codes have strong preferences on accessibility, many private venues are hard to access with only wheels. Getting on and off a truck with a lift is a hassle. There may be small steps when accessing your balcony / backyard. Even after more than 10 years since the first introduction of robot vacuum, these small wheeled robots still trap between wires, chair legs and cannot vacuum stairs at all. To get through the “last mile” problem, many people believe that legged robots will be the ultimate answer. Between bipedal, quadrupedal or hexapedal configurations, the bipedal ones seem to require the least degree-of-freedom (often means less actuators, especially the high-powered ones), thus, likely to be more power-efficient.
Many generic tasks we have today are designed for humans. It often requires the height of a human, operating with two hands, and two legs. A humanoid robot makes sense to operate these generic tasks.
The devil, however, comes from the fact that we have been building machines that can handle high-value and repeatable tasks for over a century. Many generic tasks we have today, either require high-adaptation, or low-value in itself. Through a century of standardization, these generic tasks are often both.
Have we reached a point where most high-value tasks are industrialized and the remaining tasks are the long-tail low-value ones that cumulatively, make commercial sense for a humanoid robot to adapt to? There is no clear-cut answer. To make the matter even more interesting, there are second-order effects. If the humanoid robots are successful in-volume, lower-end specialized tasks may become less economical to devise automated solutions in themselves. If you need examples, look no further than these Android-based, phone-like devices all around us, from meeting displays outside of your conference rooms, your smart TVs or even the latest digital toys for your babies. That is the economy of scale at work.
How
While people dreamed up the humanoid robots that automate day-to-day chores a century ago, it is a tricky question to answer whether we have all the relevant knowledge now to build it. We need to break it down.
1. Do we know how to build bipedals that can self-balance?
It seems that we knew this since Honda Asimo [3]. However, Asimo deployed what is often called the active dynamic walking system. It requires active control over every joint (i.e. every joint requires an actuator). This is not energy efficient.
Most demonstrations of bipedal robots fall into this category, that includes Atlas from Boston Dynamics. There are a few with some passive joints. Digit from Agility Robotics [4] is one of the known commercial products that tries to be energy efficient by leveraging a passive dynamic walking design.
Do we know how to build bipedals that can self-balance in any circumstances? Most of today’s research focused on this area: how to make bipedals walk / run faster, how to balance itself well with different weights and how to balance with uneven / slippery / difficult terrains.
For day-to-day chores, we are not going to have many difficult terrains nor to run parkours. From the system engineering perspective, falling gently would be a better proposition. On the other hand, to have any practical use, it requires to balance the bipedals with unknown weight distribution. Carrying a water bottle probably won’t change weight distribution much. But what about lifting a sofa?
2. Do we know how to build robot arms?
We’ve been building robot arms for many decades now. The general trend seems towards cheaper and more flexible / collaborative design. Many of these low-cost products consolidated around successful manufacturers such as KUKA or Universal Robots. New entrants that eyed low-cost such as Rethink Robotics had its misses. Acquisitions happened in this space and now KUKA, Rethink Robotics or Universal Robots are owned by bigger companies now.
However, high precision, high degree-of-freedom robot arms are still rather expensive. A sub-millimeter precision 6 degree-of-freedom robot arm can cost anywhere from 25k to 100k. A UR3e [5] weighs 11kg, with limited payload capacity. Arms with higher payload capacity weigh much more (> 20kg).
For home use, there are less constraints on what we can lift: repeatable precision probably can be relaxed to ~0.1 mm range rather than ~0.01mm range. Pressure sensors and pose sensors can be camera-based. We haven’t yet seen a robot arm that meets these requirements and costs around ~5k.
3. How does a humanoid robot sense the world?
A humanoid robot needs to sense the environment, make smart decisions when navigating, and respond to some fairly arbitrary requests to be useful.
During the past decade, we’ve worked very far on these fronts. Indoor LIDAR sensors [6] were used broadly in robot vacuums and the volume, in turn, drove down the cost. Any robot vacuum today can build an accurate floor plan within its first run.
Besides LIDAR, cameras came a long way to be high resolution and useful in many more settings. It can help guide the last centimeter grasp [7], sense the pressure or detect material [8]. The ubiquity of cameras in our technology stack makes them exceptionally cheap. They serve as the basis for many different sensory tasks.
4. How does a humanoid robot operate?
While we have much more knowledge on how to navigate indoor environments [9] to accomplish tasks, we are not that far with how the human-computer interface is going to work when operating a humanoid robot. Many works surrounding this were based on imitation, i.e. a human performs some tasks and the robot tries to do the same. No matter how good the imitation is, this kind of interaction is fragile because we cannot immediately grasp how generalized the imitation is going to be.
If we show a humanoid robot how to fetch a cup and pour in water, can we be assured that they can do the same with a mug? A plastic cup? A pitcher? What about pouring in coke? Coffee? Iced tea? The common knowledge required for such generalization is vast. But if they cannot generalize, it is like teaching a toddler how to walk - it’s going to be frustrating.
On the other spectrum, we’ve come a long way to give computers an objective and let themselves figure out how. We don’t need to tell our rovers on Mars how to drive - we only need to point a direction, and they can get there themselves. We also don’t need to tell our robot arms how to hold a cup - we only need to tell them to lift it up without flipping it.
We may be able to compose these discrete while autonomous actions to accomplish useful tasks. Humanoid robots, particularly those for educational purposes, have been working on the graphical programming interface for a long time [10]. However, I cannot help but feel these are much like touchscreen before iPhone: they exist and work, but in no way a superior method to interact with nor a productivity booster to accomplish things.
Where
If someone wants to invest early in this space, where to start?
SoftBank Robotics [11] has been acquiring companies in this space until recently. Their most prominent one would be the Pepper and Aldebaran’s NAO robot. However, they haven’t had any new releases for some years. Sale of Boston Dynamics doesn’t send a positive signal on their continuing investment in this space.
Agility Robotics [12] is a recent startup that focused on efficient bipedal humanoid robots. Their Digit robots are impressive and have been shipping to other companies for experimentations for quite some time. Their past Cassie bipedal robots are more open. You can download their models and experiment with MuJoCo [13] today. The Digit bipedal robots focused on the last mile (or last 100 feet?) package delivery. This puts them in direct competition against autonomous vehicles and quadcopters. The pitch is about versatility against autonomous vehicles on difficult terrains (lawn, steps, stairs), and efficiency against quadcopters (heavier packages).
Boston Dynamics hasn’t been serious about practical humanoid robots so far. On the other hand, Spot Mini has been shipping world-wide for a while now. The difficulty of a practical humanoid robot from Boston Dynamics comes from technical directions. Spot Mini uses electric actuators. Electric actuators are easy to maintain and replace. It does require some gearboxes and that can introduce other failure points and latencies. However, it can be modular thus serviceable. Atlas uses hydraulic actuators. While it provides high-force with low latency, it is expensive to maintain and breakages often mean messy oil leaks [14]. It would be curious to observe if they have any electric-actuator based variant at work.
Then there comes the Chinese. The Chinese companies working in this space are excellent at reducing the cost. UBTech’s Alpha 1E robot [15], a direct competitor to the NAO robot in the education space, is 1/18th the cost. HiWonder’s TonyPi / TonyBot [16], a much less polished product, is at 1/18th the cost too. It features Raspberry Pi / Arduino compatibility, thus, more friendly to tinkers.
That has been said, both companies are far away from a practical human-sized robot. While UBTech has been touring their human-sized robot Walker X [17] for a few years now, there is no shipping date and it looks like the Honda Asimo from 15 years ago. The company doesn’t seem to have the proper software / hardware expertise to ship such a highly integrated product. HiWonder doesn’t provide any indication that it is interested in human-sized robots. While cheap, it doesn’t seem that both of them are on the right technological path to deliver highly-integrated human-sized humanoids.
Unitree, a robotic company focused on legged locomotion, successfully shipped quadrupedal Unitree Go1 [18] at 1/25th cost of Spot Mini. Their previous models have seen some successes in the entertainment business. While mostly looked like a Mini Cheetah based [19], it is the first accessible commercial product on the market. It remains to be seen if Go1 can find its way into homes, and if so, whether that can help the company fund other quests in the home sector. The company has no official plan to enter the humanoid robot market, and even if they do, the technology requirement would look quite different than a Mini Cheetah variant.
Roborock’s robot vacuums [20] have been quietly gathering home data world-wide for some time now. On the software side and the software / hardware integration side, they are quite advanced. Their robot vacuums are generally considered to be smart around navigation. Their all-well-rounded robots have been gaining market shares around the world against iRobot at the same time, also raising the price steadily. It has been remarkable to observe how they can do both with better products. They haven’t had any stated plan to ship legged robots, not to mention a humanoid one. But their hardware has been most widely accessible among the above companies. Their software has been tested in the wild. It seems they would have quite a bit of synergy in the humanoid robot space.
At last, there is Tesla. The company hasn’t shipped any legged robots, nor any in-home robotics systems. Tesla Bot looks quite like Honda Asimo in technological direction. However, there is no technical details for exact how. The best we can guess is that these details are still in flux. That has been said, Tesla has done a stellar work at system integration when shipping their vehicles from zero to one. As we discussed above, we have these disparate technologies that somewhat can work, but to integrate them well into one coherent product, knowing where to cut features, where to retain the maximum utility, is a challenge waiting for an intelligent team to figure out from zero to one. I won’t be so quick to dismiss that Tesla cannot do this again.
This is an incomplete research note from someone who has done nothing significant in the stated space. You should do your own research to validate some of the claims I made here. Any insights from insiders will be greatly appreciated. Because the nature of this research note, unlike any other essays I posted here, I am going to provide references.
[1] https://www.youtube.com/watch?v=HUP6Z5voiS8
[2] https://www.youtube.com/watch?v=tF4DML7FIWk
[3] https://asimo.honda.com/downloads/pdf/asimo-technical-information.pdf
[4] https://www.youtube.com/watch?v=e0AhxwAKL7s
[5] https://www.universal-robots.com/products/ur3-robot/
[6] https://www.slamtec.com/en/Lidar/A3
[7] https://bair.berkeley.edu/blog/2018/11/30/visual-rl/
[9] https://github.com/UZ-SLAMLab/ORB_SLAM3
[10] http://doc.aldebaran.com/1-14/getting_started/helloworld_choregraphe.html
[11] https://www.softbankrobotics.com/
[12] https://www.agilityrobotics.com/
[13] https://github.com/osudrl/cassie-mujoco-sim/tree/mujoco200
[14] https://www.youtube.com/watch?v=EezdinoG4mk
[15] https://www.ubtrobot.com/collections/premium-robots/products/alpha-1e?ls=en
[16] https://www.hiwonder.hk/products/tonypi-hiwonder-ai-intelligent-visual-humanoid-robot-powered-by-raspberry-pi-4b-4gb, https://www.hiwonder.hk/products/tonybot-hiwonder-humanoid-robot-educational-programming-kit-arduino
[17] https://www.ubtrobot.com/collections/innovation-at-ubtech?ls=en
[18] https://www.unitree.com/products/go1
My first time going skiing was in my 20s. The software engineering job was paying me well at that time already. Why not just hire a private trainer for my ski lesson, I was thinking. Afterall, more money spent and a more focused time from the trainer ought to produce better outcomes, right? I definitely enjoyed the lesson for the first two days, but I cannot ski. The trainer was fun, and we did some practice runs on the beginner’s slope. But no, I cannot even do the pizza stop well.
The next year, I switched to a group lesson. In the first hour, I can ski from the top to the bottom on the beginner’s slope without crashing into someone or falling once. I started to enjoy the green line after two hours. The next day, I enjoyed the slopes for the whole day without any more lessons.
While in theory, if I pay enough, it is likely to find a good trainer that can teach me skiing within an hour privately. In practice, it doesn’t happen. It seems that paying money can monopolize someone’s time, but it doesn’t guarantee a better outcome.
It is not only ski lessons. You can observe this across many service industries. Private 1-on-1 tutoring v.s. public (or private) schooling. Family doctors v.s. public (or private) hospitals. Private nurse v.s. assisted living. Nanny v.s. daycare. There are many more factors in each of these industries for why money cannot buy performance (Gresham’s law etc). But you can see the theme.
The driving force of the theme is the market. In these industries, a good practitioner always makes more money when serving more people than one. When the money pooled together, it is also cheaper for the client. In return, more people can afford it. When the market is large enough, regulations can kick in. That in many cases, can guarantee a basic quality of the service.
But if I am rich, can I pay more money than the aggregate to monopolize better services? Potentially, yes. But the market is not an abstract entity with unlimited depth that can automatically facilitate transactions given a supply and demand curve. People are needed to be in the loop to either standardize the market for low-touch transactions, or to work through high-touch transactions directly.
Unfortunately, for these high-touch transactions, the market is miniscule enough that facilitating such transactions exclusively cannot be a full-time job.
That still opens the door of paying a lot more money, the amount that not only exceeds the aggregate for the best practitioners can get in the market, but also enough for a good broker to make a living.
At the end of the day, people are complicated. Serving one master is always a risky business. There are limited capacities, meaning limited upwards trajectory. People who make a reasonable amount of money for one rich person cannot be guaranteed to make more next year with the same person. Less capacities also means fewer experimentations, fewer exchanges of new ideas, and fewer ways to improve upon. You cannot fight the economy of scale any other way.
All in all, this brings us to two questions:
- Are there any service industries that haven’t enjoyed the economy of scale forementioned? We’ve witnessed the rapid industrialization of home-cooking during COVID time. Are there more?
- We’ve seen the amazing feat of the internet and software in lowering broker fees in standardized markets (stocks, commodities and housing). Can this be applied to non-standardized / one-off transactions? Can connected softwares help the price discovery and performance evaluation in any meaningful way? Airbnb tried in one specific and highly heterogeneous market. It probably is the most successful story we can tell so far. But many still questioned their performance evaluation metrics.
I don’t know the answer to either. But it will be interesting to ponder.